2021年3月号
特集
MLOpsによる機械学習プロセスの高速化と継続的にサービス価値を提供するための仕組みづくり
- 機械学習
- MLOps
- AI
MLOps(Machine Learning Operations)とはDevOpsの機械学習版で、機械学習の開発担当者とシステムの運用担当者がお互いに協調し合い、実装から商用システム運用までを円滑に進めるための概念全体を表します。昨今、技術トレンドとしてMLOpsが流⾏っておりますが、ベンダごとに定義はばらばらで統⼀的な⾒解がないと考えています。そのような背景を踏まえ、本稿ではMLOpsの背景や基本的な考え⽅に加えて、現時点で最新と考えられる検討観点や具体的な実現⼿段を中⼼に解説をします。
山口 永(やまぐち えい)
NTTデータ
背 景
AI(人工知能)を使った新規サービスの立上げや既存業務の改善を試行するプロジェクトは年々増えていますが、実ビジネスへ本格導入に至らないケースが散見されます。主な理由は2つあり、1つは限られたPoC(Proof of Concept)期間内に実業務に耐えられるレベルまでAIの精度を向上しきれないケースと、もう1つは機械学習の開発担当者が作成したAIモデルをシステム開発担当者が引き継いで商用システムへ導入しますが、コミュニケーションや作業の分割コストにより導入に時間がかかるケースが挙げられます(図1)。加えてサービス展開後の課題としては、コンセプトドリフト、またはデータドリフトと呼ばれる事象への対応が挙げられます。こちらは耳慣れない言葉ですが、一例を挙げると人の行動様式の変化を表しており、例えば昨今新型コロナウイルスの感染拡大が広まっておりますが、その影響で人の行動様式が日から週単位で変化しています。そのため、変化前にデータサイエンティストがチューニングしたAIモデルの精度が陳腐化し、役に立たなくなるケースが挙げられますが、そのような事象を指しています。
図1の課題に対するアプローチ方法として、昨今MLOpsという技術トレンドに注目が集まっています。本稿では、それぞれの課題に対するMLOps流のアプローチ方法に関して説明します。
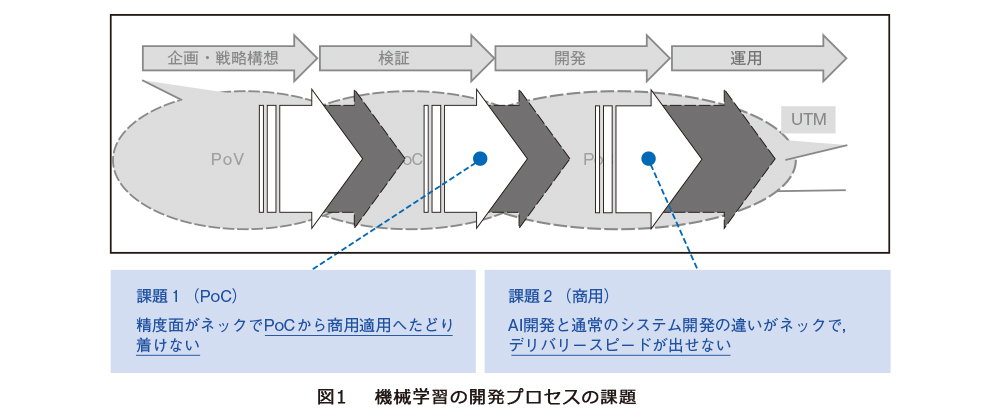
■課題1:PoC期間内にモデル精度を実業務に耐えられるレベルまで向上しきれない
1番目の課題に関しては、チューニングプロセスを効率化することで、限られたPoC(Proof of Concept)期間内でのチューニング回数を増やすアプローチが有効だと考えられています。チューニング回数を増やすことは精度向上に寄与しそうな施策がたくさん取り込まれるため、モデルの精度が向上することは直観的には正しそうに思えます。
チューニングプロセスを効率化するために、まずは俗人的なチューニングプロセスを標準化し、共通言語化したうえで、チューニングプロセスの各工程を効率化できるようなツールの導入が有効であると考えられます。
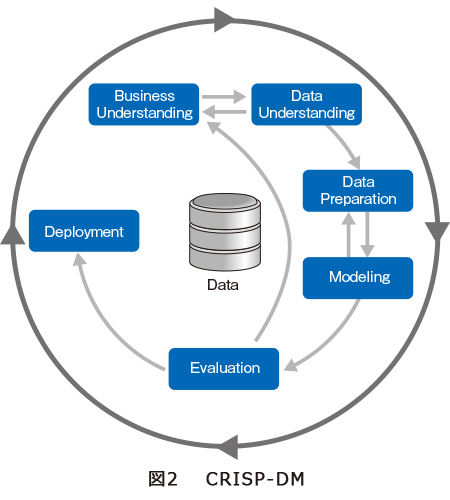
1点目のプロセスに関しては、データ分析の領域で使われている分析フレームワークが有効であると考えられています。例えば、CRISP-DM(CRoss-Industry Standard Process for Data Mining)という分析フレームがありますが、こちらのプロセスはウォーターフォールの開発プロセスとは異なり、プロセス間の行き来を許容したプロセスになります(図2)。
当該プロセスは機械学習の開発プロセスとも相性が良く、設計凍結を前提としたウォーターフォールの開発プロセスと異なり、こんな特徴量を使ったらどうなるか、アルゴリズムを変更したらどうなるかなど、試行錯誤しながら精度向上を図るのが一般的ですが、そのようなプロセスを前提としています。
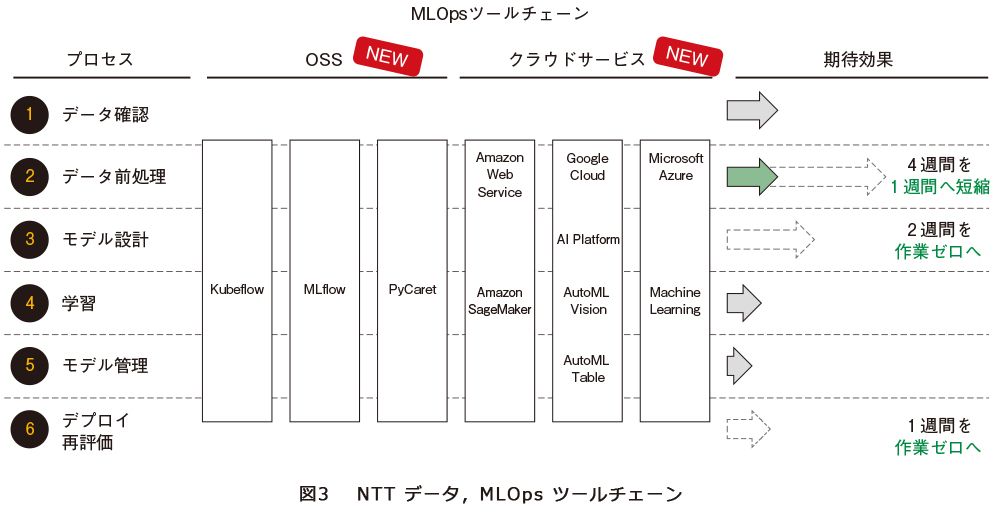
2点目のツールに関しては、機械学習の開発効率の向上を目的としたツールが、OSS(Open Source Software)、クラウドサービスプロバイダおよびサードパーティベンダから発表されているため、当該ツールの導入を図ります。NTTデータでは、以下のようなMLOps導入サービスを展開しており、機械学習のモデル開発効率に課題を持っているお客さま向けに各プロセスの効率化が可能なツール導入支援を行っています(図3)。
精度向上に直接寄与するツールの代表例として、AutoMLと呼ばれているツールが非常に有効です。こちらのツールは機械学習の開発プロセスで必要な特徴量設計やモデル設計、モデルチューニングを複数のアルゴリズムを同時に実行して、一番精度が高い機械学習を選定します。
ただし、これらのツールを駆使してAIの精度を向上させても、それがお客さまの実ビジネスへどのような効果を与えられるかを示さなければ意味がありません。そのためには、正解率(Accuracy)や再現率(Recall)といったAIのモデル精度指標をお客さまの実ビジネスの言葉に翻訳して、ビジネスインパクトを示す必要があります。
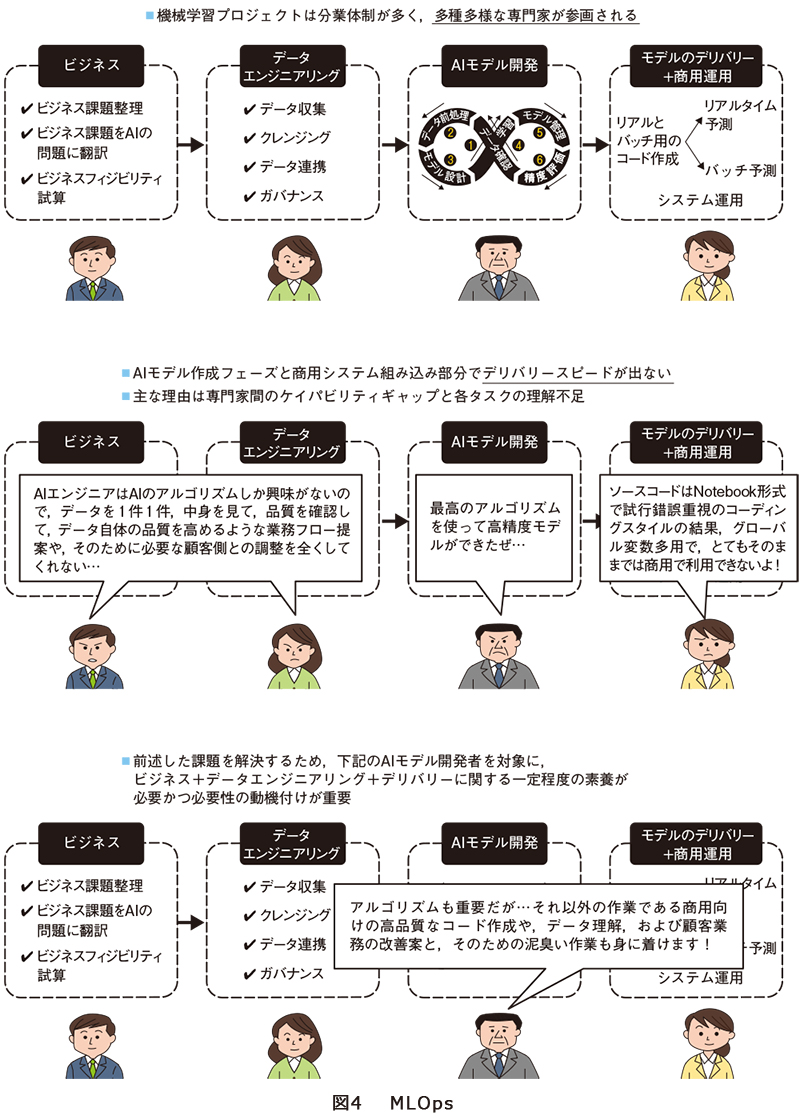
■課題2:機械学習の商用システム開発はさまざまなロールの専門家の協力が必要
機械学習の開発プロセスと、参画される専門家の所収範囲の概要を図4に示します。概要レベルでもさまざまな専門家の参画が必要になることが見て取れます。
例えばAIモデル開発者と他の専門家間で次のような課題があるプロジェクトが多々あります。
・AIモデル開発者はモデル精度向上に注力しがちだが、ビジネス&データエンジニアリング側としては、データ品質のレポーティングと品質を高めるために必要なデータ生成および業務プロセスに関する提案をしてほしい。
・AIモデル開発者は優れたソフトウェア開発者ではないため、作成したコードの品質が悪く、デリバリー側の開発者側で商用向けの高品質なコードに書き換えるコストがとてもかかる。
この点を踏まえると、AIモデル開発者のロール定義を商用開発フェーズは広げる必要があることが分かります。PoCフェーズでは必須であったモデル精度を向上させるためのテクニカルなナレッジだけではなく、商用開発向けに必要な高品質なコード作成技術やデータ理解ならびに顧客業務を理解したうえでのデータ品質改善案なども考えられる人材が必要であることが分かります。
■課題3:パンデミックなどの人の行動様式が変化する事象が発生した場合、変化前にチューニングした機械学習モデルが役に立たなくなる
昨今、新型コロナウイルスが猛威を振るっていますが、その影響で人の購買傾向の変化であったり、マスクを必須とする社会情勢からスマートフォンの顔認証ではなく、指紋認証へニーズが変化する現象があるかと思います。これはコンセプトドリフト、データドリフトの事象で、人の行動様式の変化から、発生するデータの統計的な性質が変化するため、今まで作成したモデルが役に立たなくなるという問題を表します。この事象が発生した場合の対応策としては、新たにデータを収集して、収集したデータでモデルを再構築する必要があります。ただし、毎回人手+手動で実施するのは非効率なため、機械学習システムの機能要件と仕組みとして実現し、プロセスを自動化させる必要があります。特に、一般的なアプリケーションと同様に機械学習モデルも運用フェーズが重要になりますが、前述のとおりシステム的なエラー監視の仕組みだけでは駄目で、機械学習モデルの精度監視を合わせて行う必要があります。
図5はMLOps全体の流れを表しており、①モデル開発と②デプロイだけでなく、③モデル精度監視と④学習データ作成+再学習の仕組みが必要になることが読み取れるかと思います。これらの仕組みを自動化の仕組みと合わせて導入することで、コンセプトドリフト、データドリフトの事象が発生したとしても、システムの仕組みとして対応することが可能になります。
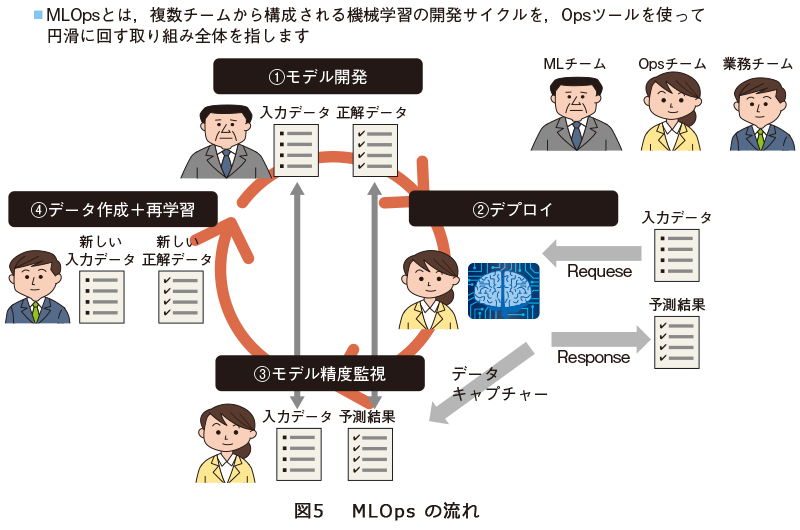
今後の展開
MLOpsは昨今の技術トレンドですが、それらを下支えする技術スタックはいまだ定義を含めて未成熟です。ただし、OSS、クラウドサービスプロバイダないしサードパーティベンダがしのぎを削って開発を進めているため、それらの動向を継続的にウォッチする必要があると考えています。
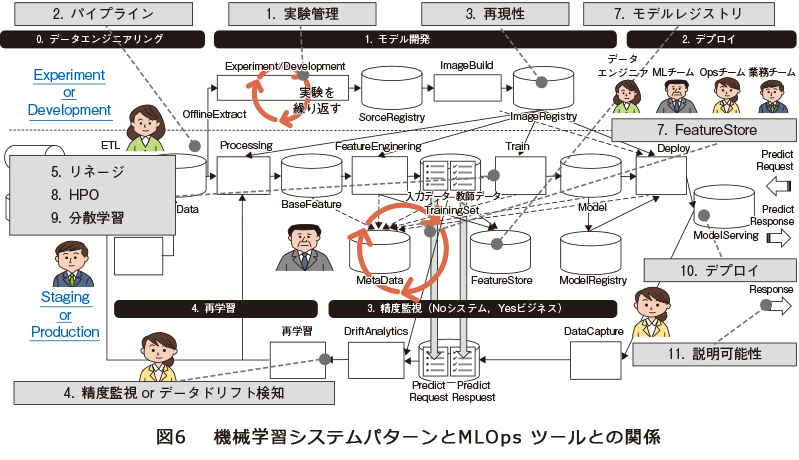
業界全体でコンセンサスが取れたMLOpsの定義はいまだ確立されていませんが、海外を含めてMLOpsに関する情報発信を行っているベンダからの情報を要約すると、システム構成(図6)とそれらを下支えする11個の機能群(表)に整理できるのではないかと考えられます。
紙面の都合上、1つひとつの機能を説明することはできませんが、今後もMLOpsツールの成熟度が高まることが予想され、それと比例してAIの社会実装が加速していくと考えられます。
そうした流れの中で、今後もMLOpsやAIの社会実装に関するさまざまなノウハウが蓄積されていきますが、それらのノウハウを活用することで、機械学習業界およびAIの社会実装の発展に寄与していきたいと考えています。

山口 永





機械学習を使った新規サービスや既存業務改善を志向するお客さまは増えている状況ですが、なかなか社会実装まで至らないケースが多いです。上記課題感で困りごとがある場合は、是非当方へご相談いただけますと助かります。