2023年4月号
明日のトップランナー
超高次元データで未来を拓く「高速スパースモデリング技術」

NTTが掲げるIOWN構想の柱の1つである、デジタル上に現実世界を構築するデジタルツインコンピューティングでは、ヒト・モノからセンサで取得されるデータを利活用することが不可欠です。しかしセンシング技術の発達によって「データの次元数が増加し、それに伴い処理時間が長くなることで、現実的な時間内でデータを分析・活用することが難しくなる」という課題が発生しています。今回はこのような課題を解決する「高速スパースモデリング技術」について、井田安俊特別研究員にお話を聞きました。
井田安俊 特別研究員
NTTコンピュータ&データサイエンス研究所
PROFILE
2014年早稲田大学大学院修士課程修了。同年、日本電信電話株式会社入社。2021年京都大学大学院博士課程修了。博士(情報学)。2022年より日本電信電話株式会社NTTコンピュータ&データサイエンス研究所特別研究員。スパースモデリングの高速化・高精度化の研究およびサービス導入支援に従事。NTTグループのAI系技術者が情報交換のために集まる連絡会(NTTディープラーニング連絡会)を運営。該当分野の複数のトップカンファレンス(NeurIPS/ICML/AAAI/IJCAI/AISTATS)にて開発技術の論文採録。
超高次元データの処理時間の増加に打ち勝つ新たな手法を創出
◆ご研究されているスパースモデリングとはどのようなものなのでしょうか。
スパースモデリングとは「得られた情報の中でも必要なものはごく一部で、その他の大部分は不要である」というスパース性を利用してデータを活用する技術です。「スパース」とは本来「まばらな」という意味であり、14世紀のイギリスの神学者オッカムの「ある事柄を説明するために、必要以上に多くを仮定するべきではない」という考え方(オッカムの剃刀)に基づいています。
そのスパースモデリングの例として、日本全国の気温・風向・気圧などの天候データから翌日の東京の気温予測を行う場合について考えてみましょう。この場合には地理的な関係性を考慮して「東京の気温予測に関連するデータは周辺の一部の都道府県だけである」という仮説が立てられます。この仮説は「全体のデータのうち重要なのはごく一部で、その他のデータは不要である」というスパースモデリングを利用するための基本的な前提になっています。このスパース性という事前知識を分析に組み込むことにより、翌日の東京の気温を予測しつつ、その予測に関連する都道府県を特定できます。
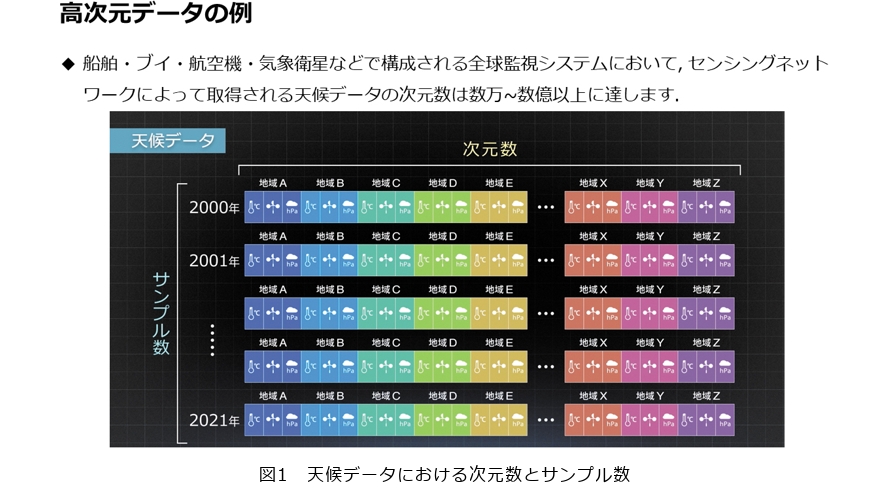
この技術が求められている背景としては、近年のセンシング技術の発達により取得できるデータの次元数が増加していることが挙げられます。例えば近年の天候分析では縦軸の年度数(サンプル数)に対して、各地域で観測できる天候情報(次元数)の数量は数万から数億にも達しています(図1)。しかし近年の機械学習は膨大な数のサンプルを学習に用いて精度を引き出すアプローチが主流であり、サンプル数が次元数よりも相対的に少ないデータを扱うことは困難です。そこでスパースモデリングでは、スパース性を用いて分析に必要な次元だけを選び出すことによって、この課題を部分的に解決しています。
スパースモデリング技術の他の活用例としては、深層学習が挙げられます。現在のAI(人工知能)の基盤技術ともいえる深層学習では、モデルのパラメータ数を増加させることによって精度を改善し続けてきました。しかし膨大なパラメータ数によってメモリ消費量や処理時間が増加するため、例えばメモリ容量に制約のあるエッジ側のハードウェアにAIを適用することは困難です。そこで「全体のパラメータのうち重要なものはごく一部で、その他のパラメータは不要である」というスパース性を深層学習に取り入れることで、AIのパラメータ数を減らしてメモリ消費量の削減などを実現しています。
◆従来技術と比較した「高速スパースモデリング技術」の強みを教えてください。
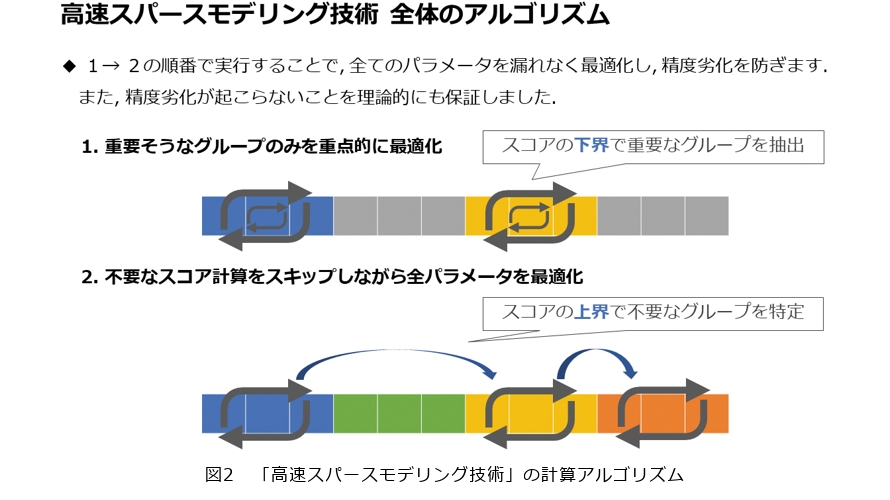
私が研究している「高速スパースモデリング技術」では、従来のスパースモデリング技術と比較して最大35倍の高速化に成功しています。従来のスパースモデリング技術では、各次元の重要度を表すスコア計算に多くの処理時間がかかっていました。一方で「高速スパースモデリング技術」では、スコアの代わりに高速に計算可能なスコアの上界・下界を用いることで、精度劣化を防ぎながら計算時間の大幅な短縮に成功しています。このアプローチは、私のNTT入社時の研究指導者であった藤原靖宏特別研究員がデータベース研究で用いていた高速化手法に影響されたものです。一見関連がなさそうなデータベースとスパースモデリングの研究を組み合わせることで、従来のスパースモデリングの研究分野にはなかった独自の方法で高速化を実現することができました(図2)。
このアプローチをベースとし、従来のスパースモデリング技術ではあまり事例がない次元数が数億以上の超高次元データを処理することをめざしています。2019年には前述した高速化アルゴリズムが最大で35倍の高速化を達成し、その論文が本分野のトップカンファレンスであるNeurIPSに採録されました。さらにこの技術をグループ会社に提供すべく1年をかけてさまざまな環境下で技術検証を実施し、本アルゴリズムによって多くの分析事例が高速化できることを確認しています。
しかし一方で、ごく少数のユースケースであまり高速化できないことも確認しています。なぜ高速化できないかを細かく分析してみると、扱うデータの性質によっては高速化アルゴリズムのスコアの上界計算のオーバーヘッド(前計算)が大きくなってしまうケースがあることが分かりました。このオーバーヘッドを極限まで削るアルゴリズムを現在開発しており、これが成功すればさらに2倍の高速化が見込めるため、35×2で最大70倍の高速化を実現できると考えています。
またそれと並行して、大規模データにおいて高い精度を達成する深層学習とスパースモデリングを組み合わせたアプローチを検討中です。深層学習は基本的に多くのデータを必要とするため、データ数が少ない場合にどのように深層学習を適用するかという研究が進んできており、この知見とスパースモデリングを組み合わせることで、データ数が少なく高次元なデータでも高い精度を達成する技術の検討を進めています。こちらはより長期的な視野の研究になると考えていて、これによってスパースモデリングの10%の精度改善をめざしています。
◆「高速スパースモデリング技術」によりどのような世界が実現されるのでしょうか。
「高速スパースモデリング技術」は、主に超高次元データから分析・予測を行うタスクに応用できます。例えば工場IoT(Internet of Things)では、生産量増減に影響がある時間帯を特定する分析の前処理で活用することで、データ分析のPDCAサイクルを高速化し意思決定までのリードタイムを短縮できます。加えて高速化によってさらに長い期間の時系列データを扱えるようになり、それまではできなかった高度な分析も可能になります。同様にゲノムワイド関連解析では、がんなどの疾患に関連する遺伝的要因(SNPs)を特定する分析の前処理へ適用できるため、高速化によってさらに大規模なSNPsデータの分析が可能となります。また核融合炉では、プラズマの崩壊や持続に関連する制御操作やセンサを特定する分析の前処理で活用し、核融合炉を安定して稼働させるための現象解明に貢献できると考えています。
そしてIOWN(Innovative Optical and Wireless Network)構想におけるデジタルツインコンピューティング(DTC:Digital Twin Computing)では、ヒト・モノに取り付けられたセンサから取得される大量のセンサデータを活用してデジタルツインを構築します。こうした未来の実現に向けた取り組みの中で、センシング技術が発達しセンサデータも高次元化しているため、高次元データ分析を得意とするスパースモデリングの利活用の機運も高まっていると思います。また高次元化が進むにつれてスパースモデリングの処理時間も増加していくため、スパースモデリングの高速化技術の確立は重要といえると思います。
◆「高速スパースモデリング技術」の研究は、今後どのように進化していくのでしょうか。
今後は空間計算量、つまり「メモリ消費量をどれだけ抑えられるか」が課題となります。高速スパースモデリング技術の高速化倍率は世界的にみてもトップクラスであり、処理時間の短縮という目的ではマイルストーンを達成しつつありますが、データが高次元になるほどメモリ消費量は当然増えるという点にも着目しなければいけません。例えば開発技術のサービス導入支援のための技術検証の現場では、高速化の倍率に問題がなくともメモリ消費量が大きすぎて処理できる次元数が頭打ちになるという事態が発生します。もちろん追加設備投資でメモリを増強してこの課題を解決することも可能ですが、サービスによってはその方法で採算が取れなくなってしまうという問題が発生します。このような課題を解決するため、高速化倍率を維持しながらメモリ消費量を抑える新たな高速スパースモデリング技術の方法を模索しています。
またもう1つの方向性として「飛躍的な高速化」があります。センシング技術の発達によってデータの高次元化が進み、いずれアルゴリズムによる高速化の限界が訪れた場合に、分散処理基盤や最新ハードウェア活用などのアプローチも含めた総合的な高速化アプローチが必要になると思います。この研究課題は他分野の専門家との連携が不可欠であり、より長期的な視野でじっくりと解決策を見つけなければいけません。NTTコンピュータ&データサイエンス研究所では先進的な計算機の研究開発にも取り組んでおり、これらをうまく活用してさらに高速なスパースモデリング技術を実現できるのではないかと検討中です。
「死の谷」の経験によって実用的な技術を創ることを決意
◆研究開発を進めるうえで、大切にされている考え方を教えてください。
学生時代に参加したベンチャー企業での教訓から「実用性を重視した研究開発」という観点を大切にしています。私は学部3年生だった2010年ごろに機械学習に初めて出会い、文書がどのようなトピックで構成されているかを可視化することができるトピックモデルという技術を研究していました。その中で「この技術を実際にサービスに組み込んでみたい」という思いが強くなり、友人からの誘いでベンチャー企業へ参加しました。しかしそこでは「想定していなかったデータが学習データに混入する」「それによってモデルが想定外の挙動をする」「出力結果が人間にとって解釈可能でなくなる」「全体のデータの規模が大きすぎて学習が終わらない」などといった研究段階にはなかった問題に多数直面し、サービスへの実装には至りませんでした。研究とサービスの間の障壁を「死の谷」と表現することもありますが、これは機械学習のサービス化において「死の谷」を越えられなかった私の初めての経験でした。こうした経験から、実際の現場の課題を解決できる機械学習技術をつくりたいという思いが芽生え、現在は「実際のサービスで動作する実用的なアルゴリズムを開発する」ことにこだわりを持って現場の方々と情報交換をしながら日々研究に取り組んでいます。
しかしもちろんそれだけではなく、飛躍的・独創的な研究成果を出すために、実用からある程度離れて長期的に取り組む研究も検討する必要があると思います。短期的・長期的研究の両方を1人で取り組むことで、例えば実用的な研究で得た知見が長期的な研究に役立ち、長期的な研究でじっくり考えていたアイデアの一部が実用的な研究に役立つこともあります。現場からの課題を実用的な研究で取り組み、そこで得た知見を長期的な研究へフィードバックする。逆に長期的な研究で熟成させたアイデアを実用的な研究に分け与えて現場の課題を解く。チャンスがあれば長期的な研究から飛躍的な結果を出せるような技術や論文をアウトプットしていく。このような2種類の異なる性質の研究の間で相互作用やフィードバックループを起こす、という状態を研究の理想形にしています。
◆最後に、研究者・学生・ビジネスパートナーの方々へメッセージをお願いします。
NTTの研究開発の分野は非常に多岐にわたり、世界的にみても独特な研究分野のポートフォリオを持っていると感じます。これは課題解決にとっても非常に有利であり、例えば深層学習高速化の案件などでは高速化倍率に関して厳しい目標を課せられることがあるのですが、NTTにはアルゴリズムからハードウェア、インターコネクトに至るまで多岐にわたる専門家がそろっているため、すぐ隣の席にいる同僚に話を聞くだけで10分もかからずに総合的な解決策を見出すことができたりします。このように難しい課題へのアプローチを短期間で考案できるというのは、独自のポートフォリオを持ち多様な研究人材がそろっているNTTの環境ならではだと思います。
また私が所属しているNTTコンピュータ&データサイエンス研究所は、データサイエンスに関して分野的にも時間軸的にも幅広いレイヤーの技術を研究している組織だと思います。例えば現場課題に密着して開発されたデータ分析技術は事業への導入が短い期間で検討されており、NTTのサービスの付加価値化に貢献していると思います。その一方で、最先端の計算機の研究開発や応用の模索は長期的なデータサイエンスの発展にとって重要な位置にあるのではないかと思います。
最後に、企業研究者として働いていると周りの状況が組織再編などによって急激に変化することがあります。このときに環境の変化へ適応しようとするあまり研究の方向を変えすぎてしまうと、それまで身に付けてきた技術力を活かせず結果が出せなくなるなどして、ストレスや自信の喪失につながってしまいます。しかし私の経験では、自分の中で普遍的でぶれない軸を持ち妥協しないようにしておくと、自分の良さを損なうことなく環境に適応できることが多いです。これは「外柔内剛」、つまり「自身の核となる研究哲学は妥協しないが、それ以外の部分は環境に応じて柔軟に適応していく」という考え方です。これを読んでいる企業研究者をめざしている学生の皆さんにも、ぜひ自分自身の軸を見つけて大切にしながら研究を楽しんでほしいと思います。




