2023年8月号
特集2
DXを実現する自然言語処理技術
- DX
- 自然言語処理
- 文書分類
近年、AI(人工知能)を利用してデジタルトランスフォーメーション(DX)の推進に資する技術開発がさかんとなっています。特に、企業に蓄積される大量のテキストデータを高速かつ正確に処理するAI技術として、自然言語処理と呼ばれる分野に注目が集まっています。本稿では、NTTドコモが開発している自然言語処理AIとその技術的特徴、およびAIの利用をサポートするGUIツールを紹介するとともに、実際の導入事例やRPAツールとの相乗効果、今後の展望について解説します。
白水 優太朗(しらみず ゆうたろう)/岡 慶介(おか けいすけ)
辰巳 守祐(たつみ しゅうすけ)
NTTドコモ
はじめに
近年、RPA(Robotic Process Automation)ツール*1やチャットボットをはじめとするデジタル技術を活用した、「働き方改革」が強く求められています。さらに、テキストのカテゴリ分類やタグ付けのように、知的な判断を必要とする作業のデジタルトランスフォーメーション(DX)はRPAツールだけでは実現が困難であることから、人間の言語理解を代替できる「自然言語処理」と呼ばれる分野のAI(人工知能)による自動処理も需要が増大しています。
しかし、実際の現場では利用できる計算資源や求められる性能が案件ごとに異なること、SaaS(Software as a Service)で社内のテキストデータを処理するのはセキュリティ面で抵抗感があること、技術者を抱えていない部門が独力でAIを導入して運用を担うのは負担が大きいことなどの諸問題があり、AIの導入は容易ではありません。
そこでNTTドコモは、計算資源を存分に活用した高性能な自然言語処理アルゴリズムを開発し、加えて、省リソースなPCでも動作する軽量高速なアルゴリズムも開発しました。さらに運用者の負担を軽減するために、GUI(Graphical User Interface)ツールも併せて開発しました。
本稿では、現場の多様なニーズに広く対応した自然言語処理AIやGUIの技術開発、ならびに社内外での活用事例について解説します。
*1 RPAツール:PC操作をシナリオとして記録させ、PC操作を自動化するソフトウェア型ロボット。
DXに推進に資する自然言語処理AI
■概要
近年、自然言語処理の学術研究が世界中で活発に行われています。これらのアルゴリズムはOSS(Open Source Software)として公開されることが多く、最新のアルゴリズムを誰でも手軽に利用できます。一方、ビジネス現場では、利用できる計算資源やデータに制約が多く、アルゴリズムをそのまま適用してもニーズを満たせません。そこでNTTドコモでは、最新のOSSも活用しつつ、前述したような現場の多様なニーズに対応するため、追加機能の開発や展開方法の工夫に取り組んできました。
■機能
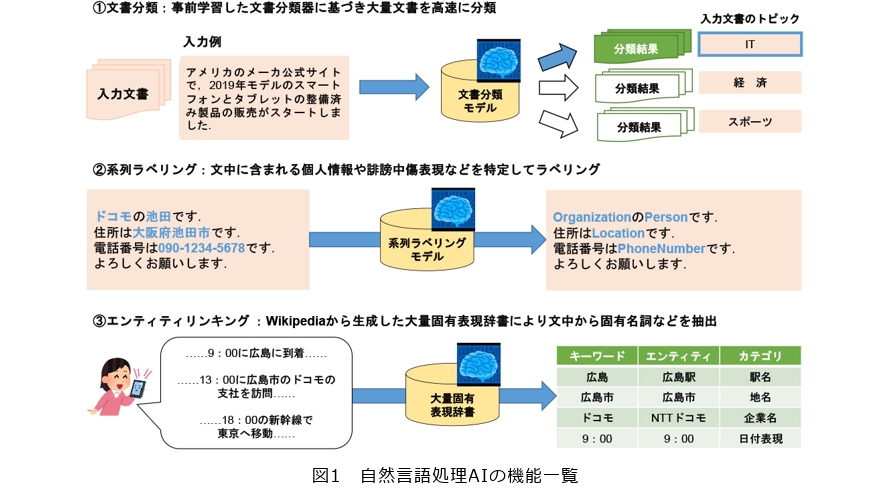
(1) 文書分類
文書分類機能は、文書にラベルを自動付与する機能です(図1①)。NTTドコモでは、ニーズに応じて、軽量な分類器と高性能な分類器の2種類の分類器を提供しています。
・軽量な分類器
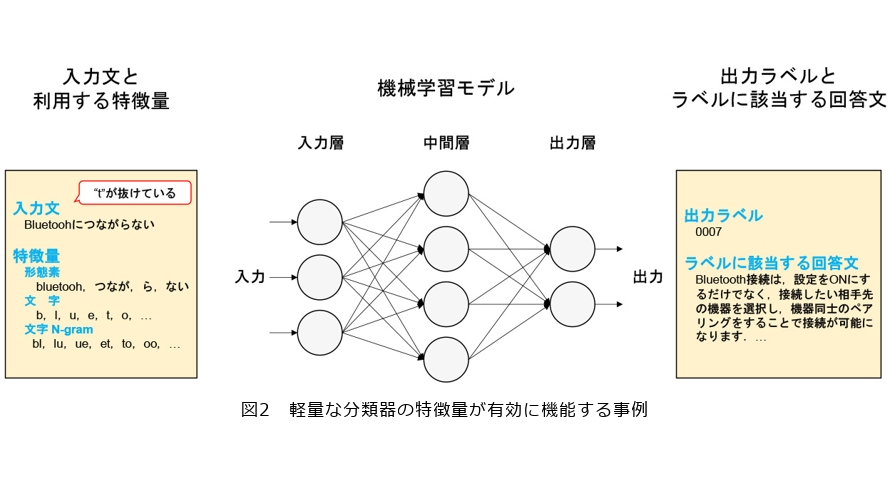
軽量な分類器は、コストやセキュリティの観点からクラウドが使えない場合など、通常業務用PCのローカル環境での利用ニーズにこたえたものです。アルゴリズムには、省リソースなPCでも実行可能な多層パーセプトロン*2を利用しています。また、特徴量として、一般的に利用される形態素に加えて、文字そのものや文字N-gram*3も利用しています。この工夫により、少量のコーパスでも高い精度が得られ、さらには誤字脱字にも頑強な分類器を構築することができます。これらの特徴量が有効に機能する事例としてFAQ分類を図2に示します。
・高性能な分類器
高性能な分類器は、GPU(Graphics Processing Unit)が利用できるクラウドサーバかオンプレミスサーバを保有している利用者の、高性能な分類器を構築したいというニーズにこたえたものです。アルゴリズムは、近年の言語処理のデファクトスタンダードであるBERT(Bidirectional Encoder Representations from Transformers)(1)を採用しました。BERTの事前学習モデル*4には、NTT人間情報研究所の成果技術であるNTT版BERTを利用しています。
また、マルチラベル分類への対応をNTTドコモ独自で行いました。NTT版BERTはシングルラベル分類しか対応していなかったですが、ビジネス現場ではマルチラベル分類のニーズが高いためです。そこで、NTTドコモでは、NTT版BERTのラベル出力部分の関数を工夫することで、出力をマルチラベル化して提供しています。
(2) 系列ラベリング
系列ラベリング機能は、系列データにラベルを自動付与する機能です。NTTドコモは、この機能を個人情報や誹謗中傷表現をはじめとする、テキストのマスキングに利用しています(図1②)。当機能の開発においてNTTドコモは、軽量なアルゴリズムを扱えて、かつ開発者コミュニティの大きいOSSとして知られるFlair(2)を採用しました。
(3) エンティティリンキング
例えば、「ドコモ」「DOCOMO」といった語は、一般的な単語(例えば、「机」や「電車」など)とは違い、固有名詞です。さらに、これらの語は文字列こそ異なるものの、いずれも「NTTドコモ」という同一の概念(エンティティ)を指しています。このように、「文中の何がキーワードか」「そのキーワードがどのエンティティを指すか」を機械的に抽出・推定する機能がエンティティリンキングです(図1③)。
・Wikipediaからの抽出データに基づく辞書の構築
NTTドコモでは、特にWikipedia(3)から抽出したデータをエンティティリンキングに活用しています。Wikipediaを利用する利点として、①更新が頻繁であり新語や流行語などへの対応が早いこと、②毎日新たにデータベース・ダンプ*5が公開されておりデータを利用しやすいこと、③データ抽出から辞書構築までを一気通貫で自動処理できるため、辞書のメンテナンスコストが低いことが挙げられます。
・カテゴリの付与
NTTドコモでは、「拡張固有表現階層*6」(4)に基づくカテゴリを上位概念としてエンティティに付与しており、抽出した結果を200種類程度のカテゴリに分類した上で、それらを利用します。
・活用事例
例えば、ニュースからのキーワード抽出が挙げられます。Wikipediaは時勢を反映して記事内容が更新されたり特定のページ閲覧数が伸びたりするため、Wikipediaの統計データを利用したエンティティリンキングは、ニュース本文からのキーワード抽出と相性が良いです。加えて、単純な文字列抽出のみではなく「表記ゆれの吸収」も同時に行うため、抽出・リンキングされたエンティティあるいはエンティティに付与されたカテゴリを記事のタグとして活用しやすいというメリットがあります。
*2 多層パーセプトロン:機械学習アルゴリズムであるニューラルネットワークの一種。
*3 N-gram:任意の連続したn個の要素。要素の例としては、単語や文字などが挙げられる。
*4 事前学習モデル:目的タスクの教師あり学習実施前に、大量のコーパスで教師なし学習したモデル。
*5 データベース・ダンプ:データベースの内容をそのままファイルに出力したもの。
*6 拡張固有表現階層:語を「人名」「市区町村名」「国名」のような200種類程度のカテゴリに分類したもの。カテゴリは「地名>天体名>惑星名」のように、最大3階層の構造になっています。
自然言語処理AIの展開を加速するGUIツールの開発
■概要
自然言語処理AIの導入や活用には、AIの精度を維持・向上していくためのチューニングが欠かせません。チューニングとは、AIの精度検証、アノテーション作業による学習データの修正など、AIモデルの構築と継続的な更新に発生する一連の作業を指し、一定の人的な運用コストが発生します。
このような作業にかかる運用コストを軽減するために、NTTドコモはAIのチューニングをサポートするGUIツールも併せて開発しています。GUIツールとツールのバックエンド*7エンジンはコンテナ仮想化技術*8の上で動作させており、バックエンドからフロントエンドまでを簡便に導入できます。
*7 バックエンド:GUIを動作させるためのシステム部分。主にエンジンおよびエンジンとGUIの動作をつなぐシステム部分のこと。
*8 コンテナ仮想化技術:アプリケーション本体や、アプリケーションに必要なファイル群を「コンテナ」としてパッケージングし、コンテナエンジンというプロセス上で動かす技術の1つ。
■GUIツールの開発とその機能
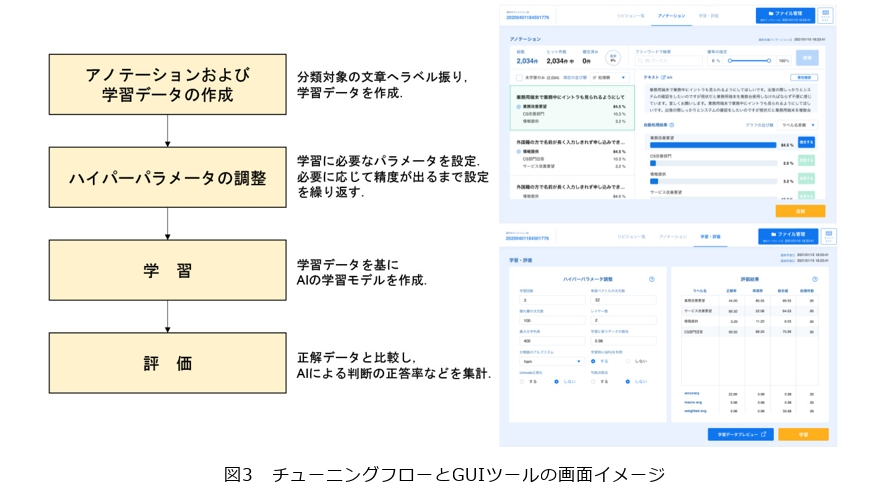
本ツールでは、AIの構築に必要なデータセットのアップロード、アノテーションデータ作成、学習、評価など一連の機能をGUIとして提供しており、AIの初期構築からメンテナンスに至るまでのすべてをツール画面上で実行可能です(図3)。
主な機能詳細を以下に示します。
(1) 学習・評価
あらかじめ用意したアノテーション済みのテキストデータをツール経由でアップロードし、簡易な画面操作を行うことで、独自のAIを作成できます。また、正解として用意したアノテーション済みデータをGUIツールへアップロードすると、本ツールが正答率を自動で算出し、作成したAIの精度を評価できます。
(2) チューニング
学習済みのAIを用いて、テキストデータに自動でラベルを付与する機能と、ユーザがラベルを確認・修正できる機能を提供しています。ある程度学習を繰り返したAIにテキストのアノテーションを任せ、間違った部分を人間の判断で修正することでアノテーションの作業の効率化が可能となります。そして、アノテーションしたテキストをさらにAIに学習させることによる精度向上も可能です。
また、学習時のハイパーパラメータの変更、学習実行、精度評価などが実行できる画面も提供しており、チューニング時のパラメータ調整が容易です。
(3) リビジョン管理
本ツールでは、学習したAIや学習に利用したデータセット、評価サマリなどを、「リビジョン」という作業単位ごとに管理できる機能を提供しており、前述したような煩雑な管理をユーザが意識することなく、過去のデータセットや評価サマリをシステム側で個別に管理し、各データセットのチューニングの効果やデータの差分を分析することが可能です。
活用事例の紹介
■概要
NTTドコモでは、自然言語処理AIやGUIツールの開発のみならず、社内外で自然言語処理AIによるDXを推進しています。
社内においては、ユーザや従業員からの意見・要望がテキストデータとして集約されるCS(Customer Satisfaction)部門と相互に協力し、自然言語処理AIの構築や導入サポート、蓄積してきた人手による分類結果の共有などを通して、ユーザ満足度向上のためのオペレーション改善に努めています。
また社外においても、法人営業部門と共同でRPA - AI連携ソリューション展開を進めており、自然言語処理のみならずOCR(Optical Character Recognition)や音声認識技術をも活用した実証実験を広く実施しています。
■社内CS部門との取り組み
NTTドコモでは、ユーザや従業員からいただいた意見・要望を、特定の個人を識別することができないように加工した上で分析・分類し、ユーザ満足度や従業員満足度の向上につながるようなサービスを開発したり業務の改善に活用したりしています。しかし、日々届くアンケートは大量であることから精読には時間がかかります。また、人の目で確認する以上、見落としや分類ミスなどによる精度の低下などは避けられません。
そこでNTTドコモは、自然言語処理AIの導入によるアンケート自動分類を社内CS部門と進めてきました。自然言語処理AIを作業に導入することで、これまで長時間人手をかけて実施していた内容の大半が自動化され、大きな稼働時間の削減効果がありました。今後はアンケートの自動分類のみならず、ユーザが誤って入力してしまった氏名や住所などの個人情報を、人の手を介さずに自動で秘匿するAIを導入することで、ユーザに、より一層満足いただける価値の提供をめざします。
■RPAツールとAIの連携ソリューション
近年、自然言語処理やOCR用のAIを「頭脳」に見立ててRPAツールと組み合わせることで、より複雑な業務を自動化するソリューション(Cognitive Automation*9)が模索されています。NTTドコモにおいても、RPAツール「WinActor」の導入・拡大およびRPA - AI連携ソリューションの一環として、「既存システムへの電子カルテ自動投入」の実証実験を、奈良県総合医療センターと共同で実施しました。
医療現場には、患者ごとのカルテ作成や電子カルテシステムへのデータ入力など、ITによる効率化が可能な業務も多くありますが、RPAツールのみでの対応は容易ではありません。また、個人情報を扱うことから、作業用PC間のローカルネットワークに閉じた処理が比較的好まれます。
以上の点を踏まえ、ローカルでも動作する軽量な自然言語処理AIと外部サーバの不要なRPAツールを、院内のローカルネットワークに接続しているPC上のみに構築し、それらを連携させて、これまで人間が実施していたシステムへの転記作業をそのまま自動化することで、医療従事者の稼働削減による超過勤務解消を図りました。さらに音声認識ソフトを新たに導入し、これまで紙に控えていた患者情報を音声発話から直接電子テキスト化することで、データ作成の効率化もめざしました。
実証実験の結果、電子カルテシステムへの投入時間削減といった定量的な効果のみならず、「記入ミスの削減につながった」「患者と向き合う時間が増えた」という担当者からの定性的な評価もありました。
*9 Cognitive Automation:自然言語処理や画像認識、音声認識などのAIとRPAツールとを組み合わせることで、人間が行っている「判断に基づく作業」を自動化すること。
おわりに
本稿では、DXを実現する自然言語処理アルゴリズムの開発、操作性・利便性を向上させるためのGUIツールの開発、および社内外への展開と今後の展望について解説しました。複数種類の手法やアルゴリズムをサポートした多様な自然言語処理AIを開発することによって、利用者は、用途や要件、実行環境などに合わせた適切なAIの選択が可能になりました。並行して、運用部門からの機能要望を盛り込んだGUIツールを開発することで、現場でのAI運用(学習、性能評価、精度改善)の負担軽減をめざしました。さらに、開発した自然言語処理AIを導入・活用することで、稼働を定量的に削減できるだけでなく、RPAツールとの親和性の高さや、業務フロー改善に伴って作業の質が向上するといった効果も示せました。
今後は、新規アルゴリズムの追加などバックエンドの機能拡張と並行して、社内外での活用事例創出や利用組織拡大に向けてフロントエンドのGUIツールを訴求していきます。
* 本記事は「NTT DOCOMOテクニカル・ジャーナル」(Vol.29 No.4、2022年1月)に掲載された内容を編集したものです。
■参考文献
(1) J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova:“BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding,” Proc. of NAACL, May 2019.
(2) A. Akbik, T. Bergmann, D. Blythe, K. Rasul, S. Schweter, and R. Vollgraf:“FLAIR:An easy-to-use framework for state-of-the-art NLP,”Proc. of NAACL, June 2019.
(3) https://ja.wikipedia.org/wiki/
(4) http://ene-project.info

(左から)白水 優太朗/岡 慶介/辰巳 守祐







近年の技術的革新によって、自然言語処理は著しい進展を遂げ、非常に注目されている分野となっています。業務効率化や働き方改革だけでなく、より幅広い領域で有用な技術の研究開発に、今後も取り組んでいきます。