2024年6月号
挑戦する研究者たち
特定分野の専門知識を持った高性能で低消費エネルギーのLLM、tsuzumi

2022年11月に生成AIであるChatGPTが発表され、それ以降大規模言語モデル(LLM:Large Language Models)が世界的に急速に注目されるようになりました。以降次々と新たなLLMが発表される中、高性能という「明」に対して消費エネルギーの増大という「暗」の部分もクローズアップされてきています。2023年11月1日に発表されたNTT版LLM「tsuzumi」は、「LLMの大規模化・一極集中化ではなく、異なる個性を持った多数のAIが連携することにより、ヒトと一緒に社会のWell-beingを実現する未来をめざす」ことをビジョンに開発が進み、「明」の実現と「暗」の解決を同時に成し遂げることが可能になり、2024年3月25日に商用開始が発表されました。NTT人間情報研究所 西田京介上席特別研究員に、tsuzumiのプロジェクト発足経緯・特徴、LLMの動向、そしてレッドオーシャンに向けたチャレンジについての思いを伺いました。
西田京介
上席特別研究員
NTT人間情報研究所
発表から商用開始までを5カ月で達成。NTT版LLM「tsuzumi」
現在、手掛けていらっしゃる研究について教えていただけますでしょうか。
2023年11月に発表しましたtsuzumiをはじめとする、大規模言語モデル(LLM:Large Language Models)の研究をしています。
2009年にNTT入社以降、2013〜2015年に事業会社に在籍した期間も含めて、さまざまな研究開発を行ってきました。2017年ごろから取り組み始めた自然言語処理分野の研究では、AI(人工知能)による自然言語テキストの「機械読解」、人が目からテキストを読むようにテキストと併せて視覚情報も融合させて理解させる「視覚的機械読解」等のテーマに取り組み、言語処理学会年次大会(NLP)で2018〜2024年に優秀賞(2018年、2021年は最優秀賞)を受賞し、ICDAR(International Conference on Document Analysis and Recognition)という文書解析・認識に関する国際会議における、2021年のVQA(Visual Question Answering)コンペティションでは、2位に相当するrunners-upを受賞しました。
特に、2018年にGoogleからBERT(Bidirectional Encoder Representations from Transformers)という言語モデルが発表され、NTT版の日本語BERTをつくる話が出てきたころから、言語モデルに関する研究に取り組むようになりました。2022年11月に生成AIであるChatGPTが発表されLLMが世界的に注目されるようになるのと並行して、これまでになかった汎用AIの初期段階の登場とも思えるようなパラダイムシフトが世界で進行していることを感じ取り、NTTとしてもLLMに取り組む必要性・重要性を訴求して2023年2月にLLMに関するプロジェクトを立ち上げ、それ以降LLMをメインのテーマとして取り組んでいます。
プロジェクトでは、コンピューティングリソースの調達や学習に必要なデータの収集から手掛け、チームメンバーとともにLLMの構築に取り組みました。6月ごろからLLMの事前学習を行い、11月1日にtsuzumiを発表し、2024年3月25日に商用利用開始の発表、という非常に短期間での開発となりました。
LLMとはどのようなものなのでしょうか。
言語モデル(LM:Language Models)は、単語(トークン)列の生成尤度をモデル化し、将来の(あるいは欠落した)トークンの確率を予測することで結果を得るモデルです。LLMは、Transformerと呼ばれるニューラルネットにおける深層学習モデルをベースとしており、高精度な情報検索やプログラムの生成・修正を含むさまざまな言語処理タスクを可能にします。LLMの高度な言語処理能力は、主として「事前学習」「インストラクションチューニング」の2つのプロセスを経て実現されます。
事前学習は、言語モデルを事前学習させるプロセスで、Transformerを大量のテキストによる大規模コーパスにより事前学習し、事前学習済言語モデルをつくります。2018年のBERTの登場から、この言語モデルが自然言語処理の基盤として有効であると注目を集めています。2020年に登場したGPT-3では、タスクを定義したプロンプトに続くテキストを生成させることにより、ファインチューニングせずとも任意のタスクをある程度扱えるほど、事前学習済言語モデルの能力が発展しました。
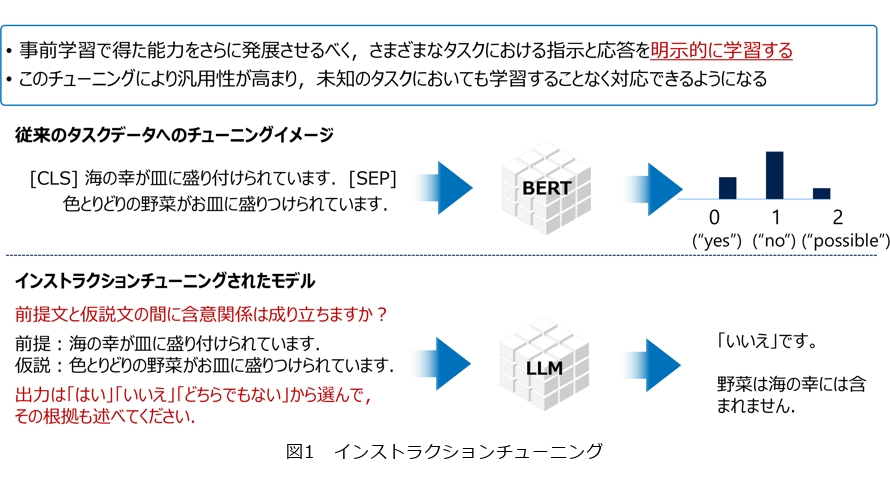
インストラクションチューニングは、事前学習で得た能力をさらに発展させるべく、さまざまなタスクにおける指示と応答を明示的に学習するプロセスです。従来のタスクデータへのチューニングでは、例えば、2つの文章をセパレータと呼ばれるトークンで渡してBERTに入力することで、0(“yes”)、1(“no”)、2(“possible”)といった3つのラベルがついたスコアを出し、これで入力した2つのトークンの関係性を判定していました。これはデータドリブンな学習で、言語モデル自身はどのようなタスクが与えられているかを全く知らない状態でデータドリブンに学習を行います。一方、インストラクションチューニングでは、これらのタスクを言語で定義していきます。入力テキストに対して、どういうタスクを解いてほしいのか、どういう出力をしてほしいのかということを言語で定義し、LLMがその指示にしたがって答えてくれるようにするチューニングです(図1)。これにより汎用性が高まり、未知のタスクにおいても学習することなく対応できるようになります。
さて、現在のLLMは大規模化する傾向にあり、Scaling Raws*に基づき、モデルサイズ(パラメータ数)の大きな言語モデルが次々とつくられており、パラメータ数が1 T(Trillion)=1000B(Billion)=1兆規模を超えるモデルも開発に入っています(図2)。例えばGPT-4ではパラメータ数が1.76Tともいわれています。一方で、この傾向が進むにつれて、エネルギー消費も指数関数的に増大し、コストもそれにつれて増大します。175Bのパラメータを持つといわれているGPT-3でモデルを学習しようとすると、1回の学習で原子力発電所1基分に相当する、約1300MW/hのエネルギーを使うという試算もあります。
*Scaling Raws: 自然言語処理モデルのモデルサイズ(パラメータ数)、データセットのサイズ、トレーニングに使用される計算量が増えるにつれて、損失が「べき乗則」に従って減少するという法則。

鼓とtsuzumi、キーワードは「日本語」「小型軽量」「柔軟なチューニング」「マルチモーダル」
tsuzumiはどのようなLLMでしょうか。
何でもできる汎用的なLLMに向けて大規模化が世界の潮流にある一方で、エネルギー問題が課題となってきています。そこで私たちは、「LLMの大規模化・一極集中化ではなく、異なる個性を持った多数のAIが連携することにより、ヒトと一緒に社会のWell-beingを実現する未来をめざす」ことをビジョンに、モデルサイズで対抗するのではなく、特定分野の専門知識を持った高い性能のLLMを、言語学習データの質と量を向上させるというアプローチでtsuzumiを開発することとしました。ここで、「異なる個性を持った多数のAIが連携する」については、例えば医療分野や教育分野に強いLLMといったような、小型で性能が良い複数のLLMが連携することで、全体として良いLLMを形成する「AIコンステレーション」というコンセプトに基づいています。そして、私たちのLLMの特徴である「日本語に特に強い」「小型・軽量ながらも良い性能を持つ」「チューニングが柔軟に行いやすい」「そしてマルチモーダルへの拡張ができる」という点を楽器の鼓になぞらえて、tsuzumiと命名しました(図3)。
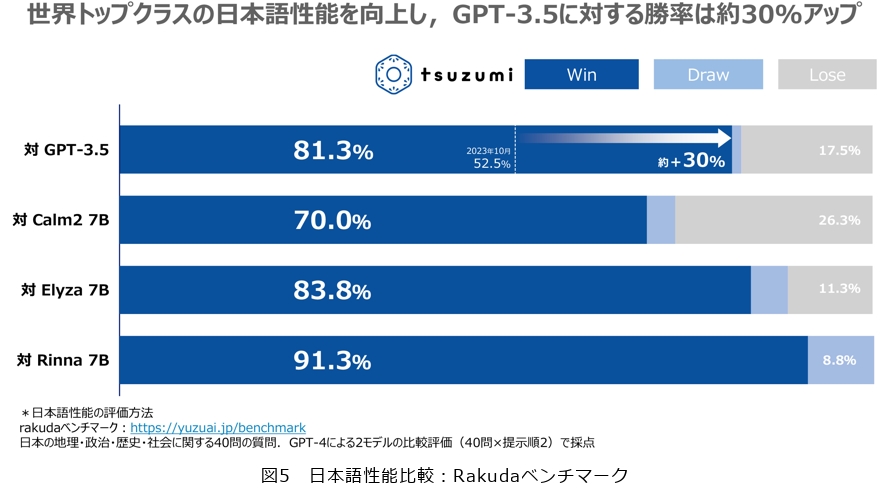
tsuzumiの評価に関しては、日本の地理・政治・歴史・社会の4カテゴリに関する40問の評価セットにより、2つのモデルの出力を比較して評価を行うRakudaベンチマークでの結果を紹介します。このベンチマークでは、人間による評価の代わりにGPT-4を評価役として用います。図4に示す評価例では、GPT-4がtsuzumiとGPT-3.5の出力を比べて、具体性や詳細度の観点でtsuzumiを高く評価しています。ベンチマーク全体としては、GPT-3.5や他の日本語向けLLMに対して勝率が大きく上回る結果になっており、tsuzumiが高い日本語の理解・生成能力を持っている1つのエビデンスとなっています(図5)。
tsuzumiの事前学習については、専門文書からエンタテインメント系まで幅広いドメインで、合計1000Bを超えるトークン数を用意して事前学習を行いました。今後、さらに学習データの質や量については改善をめざしていきます。また、事前学習中の言語の比率についても重要で、限られた日本語コーパスを基に日本語に強いLLMを構築するためにどのようなバランスで事前学習すればよいのか、という点はまだ明らかになっていません。最近では、海外製のLLMをベースに、日本語を追加で学習する方式も採用されており、これも非常に良い結果を生み出しています。私たちは、内製でゼロから独自に事前学習を行いました。日英中心にコードや多言語のデータも加えています。特に多言語を加えることの効果など、今後さまざまな観点から検証を行っていきます。
事前学習コーパスの作成においては、文章をトークンに分解するトークナイズや前処理についても注力しています。トークナイズについては日本語の単語を考慮した分割を実施しています。単語の制約を考慮しない場合、学習コーパスの偏りから発生する不自然で冗長なトークンが生まれやすくなってしまいますが、私たちのトークナイザは、長年取り組んできた単語分割に関する研究成果を活用することで、自然な単語の分かち書きに近い分割になります。また、できる限りテキストの質を高めるため、さまざまな方式で、ノイズとなるテキストを除去する作業を行っています。
インストラクションチューニングについては、幅広いカテゴリの質問や指示でインストラクションチューニングデータを独自に整備して学習に利用するとともに、有益性および安全性の両面から、データの整備を現在も拡大しています。


tsuzumiが商用サービスを開始しましたが、今後どのような展開をお考えでしょうか。
メディカル領域やソフトウェア開発など、専門用語や業界に特有の表現が多く含まれる場合は、従来の生成AIが十分な性能を発揮しないケースも多々あると思います。tsuzumiは、こうした業界に特有のデータに対してもカスタマイズが可能なため、AIを活用できる領域を広げることができます。また、顧客サポート領域では、お客さまのCX(Customer eXperience)向上のために、図表等のマニュアル類の読解とお客さま情報のアップデートによるパーソナライズが不可欠です。tsuzumiは、世界トップクラスの日本語処理能力とともに図表読解もサポートしていくことで、コンタクトセンタや相談チャットボット等顧客サポート領域における進化を支援します。
特にメディカル領域においては、日本では電子カルテの導入は進んでいますが、同じ症状でもカルテの書き方は病院、医師により異なるため、カルテデータを集積して分析活用することが困難な状況でした。tsuzumiは、超軽量で柔軟に、またセキュアにカルテデータを処理できるため、ドクターが記録した医療データを読解し、共通フォーマットに適切な表現で配置し、分析できる状態にします。
また、NTTドコモのコンタクトセンタでは、お客さまから年間4000万件以上の問い合わせを受けています。現在、コミュニケーターやチャットボットが応対していますが、マニュアル類の種類も多く、新しい情報が追加される頻度も高いため、適切な回答の作成や、チャットボット用のQ&A作成に対して多くの手間がかかっています。tsuzumiを導入することで、通話内容や図表入りのマニュアルを正しく理解してお客さまのご要望を適切に把握し、最適な回答をお返しできるようになると考えています。
2024年3月25日にtsuzumiのサービス開始をニュースリリースしましたが、研究のフェーズとしては基盤になるモデルをつくったところであり、それをNTTグループ全体のエンジニアとともにお客さまに価値を提供していくためにブラッシュアップしています。私はそれをサポートするとともに、AIコンステレーションを含めてtsuzumiを汎用化し、人とAIが自然に共生する世界をめざして研究を進めていきたいと思います。LLMは目覚ましい発展を遂げていますが、社会実装を進め、AIがあらゆる環境で人を支援するためにはまだ不足している点が多いです。特に、AIが人と同等の入出力インタフェースを持ち、マルチモーダルなタスク、身体性を必要とするタスクに取り組めるようにすることが重要です。現在、私たちは視覚と言語の融合理解をメインに取り組んでいますが、今後、聴覚、力覚、触覚、さらには脳波などの生体信号を言語モデルとどのように結び付けていくかについて取り組んでいきたいと考えています。
今重要なこと、今自然にやるべきことをめざすという意識でチャレンジ
研究者として心掛けていることを教えてください。
私は研究を進めていくうえで、「アカデミックとビジネスの両方に関与することをしたい、その時々で皆が自然にやるべきだと思える重要な研究をしたい」という思いを持っており、チームのメンバーにもよく話しています。2017年ごろは、表データを人のように読む「表の読解」をテーマとして取り組み、それがコンタクトセンタのソリューションに利用され、その後2018年ごろに、自然言語を理解・生成する機械読解・要約に取り組み、COTOHA®というNTTコミュニケーションズのサービスに利用されました。そこから視覚的な文章読解というような、より人間に近い条件下で人間の言葉を理解させる方向性に進んできており、その時々の技術レベルに応じて価値を創出できるテーマに対してアプローチすることを実践してきました。そして、現在はLLMに取り組んでいます。LLMは競争の激しい分野であり私にとっても非常に大きなチャレンジだったのですが、このタイミングでNTTも絶対に取り組むべきだという思いで、プロジェクトを立ち上げました。
さて、機械読解を研究テーマとしているとき、初めてMS MARCOというMicrosoft主催の機械読解を競い合う国際的なコンペティションにチャレンジしてみました。それまで、たくさんの研究者が参加する主要なテーマで戦うという経験はありませんでしたが、私たちのモデルが当初1位になり、リーダボードの最上位にNTTの文字が載りました。自分自身もすごく嬉しかったのですが、周りの人もとても喜んでくれたことが印象に残っています。このときの経験から自分たちも世界で戦っていけると思い、その後もいくつかのコンペティションやリーダボードに参加して、上位の成績を取ることができました。LLMは世界中が注目しており、その進化も日進月歩なので、LLMに取り組むことには勇気が必要でしたが、MS MARCOの成功体験が私の背中を押してくれたと感じます。LLMはビジネスからもとても期待が大きいですし、アカデミックなテーマとしても、LLMのメカニズムの分析から新しいモデルの提案まで可能性を多く秘めているので、大きなやりがいを持って取り組んでいます。
後進の研究者へのメッセージをお願いします。
メインストリームにある分野の研究テーマは、多くの研究者が切磋琢磨しているレッドオーシャンであり、なかなか成果が出にくい環境であるため避ける方もいると思います。一方で、今一番重要なテーマであるからこそ、たくさんの研究者が取り組んでいるともいえます。実際に自分たちでやってみると新しい発見や手ごたえがあり、十分に戦っていける部分が多いと思いますので、若い研究者の方にもぜひチャレンジしていただきたいです。一方、メインストリームではないが新しいテーマに取り組むときは、それをやることで他の研究者が後ろからついてくるような価値のあるテーマになっているかを意識して取り組むのが良いと思います。例えば、若いころはややインクリメンタルであっても重要と思えるテーマに取り組み、より実力が付いてきたらメインストリーム、レッドオーシャンのテーマであっても覚悟を持って飛び込んでいくということもあるのではないでしょうか。いずれにしても重要で価値のあるテーマにチャレンジすることが大切と考えます。
LLMについては多くの研究者が取り組む、まさにレッドオーシャンではありますが、一方で歴史の浅く、変化が激しい分野でもあるため、全く追いつけないということはなく、最前線で戦っていける可能性が十分にあるテーマだと考えています。たくさんの方に協力いただきながら進めており、これから良い成果が出せると期待しています。
さて、研究分野やテーマを変えることは勇気がいることではあると思いますが、自然言語処理以外もさまざまな分野・テーマに取り組んできた自分の経験からは、柔軟にいろいろなことにチャレンジしてみて良かったと思います。今重要なこと、今自然にやるべきことをめざすという意識でチャレンジすれば、分野・テーマを変えることに対して、比較的抵抗が少ないのではないかと思います。






