2019年7月号
機械読解による自然言語理解への挑戦
- 機械読解
- 自然言語理解
- 深層学習
AI(人工知能)の文章読解力に注目が集まっています。AIに人間が用いる言葉(自然言語)を理解させることはとても難しい課題ですが、近年では深層学習の適用により大幅にAIの読解力が向上しました。本稿では、マニュアルに書かれた業務知識を理解し、お客さまの言葉を理解して質問に適切に応答するエージェントの実現をめざして研究開発を進めている機械読解技術について紹介します。
西田 京介(にしだ きょうすけ)/ 斉藤 いつみ(さいとう いつみ)/ 大塚 淳史(おおつか あつし)/ 西田 光甫(にしだ こうすけ)/ 野本 済央(のもと なりちか)/ 浅野 久子(あさの ひさこ)
NTTメディアインテリジェンス研究所
機械読解と自然言語理解
コンタクトセンタにおけるお客さま応対をAI(人工知能)技術により支援するために、NTTメディアインテリジェンス研究所(MD研)では機械読解について研究開発に取り組んでいます。機械読解とはAIがマニュアルや契約書などのテキストを読んで質問に応答する技術で、人間が日常的に用いる言葉を理解する「自然言語理解」の実現に挑戦するものです。コンタクトセンタでは、検索用にマニュアルからFAQを事前に準備しなくても、マニュアルに書かれた内容を正確に読み解いてピンポイントに回答を発見することでオペレータを支援することをめざしています(図1)。
機械読解は新しい研究分野ですが、深層学習の発展および大規模なデータセットの整備により急速に発展しています。特に、スタンフォード大学が作成した機械読解データセットSQuAD(1)において、2018年1月にAIが人間を上回る回答精度を達成したことで、この研究分野に大きな注目が集まりました。しかし、SQuADの問題設定は比較的単純であり、より難しい問題設定においてAIはまだ人間の読解力には及びません。MD研では、研究用のデータセットを用いた学術的な競争の中で技術を磨きながら、コンタクトセンタにおける実用化に向けた課題の解決に取り組んでいます。本稿では、私たちの機械読解に関する研究成果について紹介します。
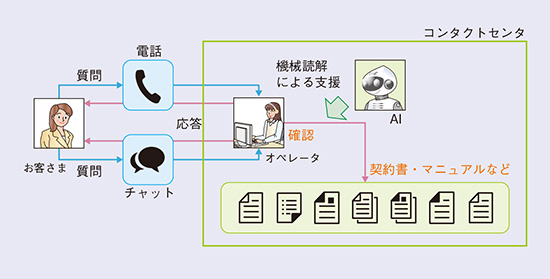
図1 コンタクトセンタと機械読解
多数のテキストから回答を発見する「大規模機械読解技術」
初期の機械読解研究の問題設定では、知識源として扱うテキストは1つに限定されていました。しかし、コンタクトセンタをはじめとした実際の応用シーンでは、多数のテキストから質問に対する回答を発見する必要があります。すべてのテキストを機械読解モデルにより詳細に読み解くのではシステム動作が遅くなってしまうので、回答に必要な文書を高速かつ正確に絞り込まなければなりません。
そこでMD研では、大規模機械読解技術を確立しました(2)、(3)。この技術は、まず高速に動作するキーワード検索技術を用いて質問に関連するテキストを大まかに絞り込み、次にニューラル検索モデルにより正確にテキストを絞り込み、最後にニューラル読解モデルにより回答を発見します(図2)。この際、ニューラル検索・読解を同時に1つのモデルで学習することで、検索精度が大きく向上しました。これにより、英語Wikipediaの500万記事を知識源とした機械読解タスクにおいて、発表当時世界最高の回答精度を達成することができました。

図2 大規模機械読解
複数個所に書かれた根拠を理解し提示する「説明型機械読解技術」
機械学習に基づくAIでは回答が正しいことを100%保証することは難しいため、機械読解モデルが出力した回答の妥当性を人間が確認できることは重要な機能となります。人間が回答の妥当性を確認するためには、回答の根拠となる情報がテキスト中のどこに書いてあるのかを機械読解モデルが提示することが有用となります。しかし、回答の根拠となる情報はテキスト中の複数の文に分かれて記述されているケースがあるため、これらすべてを理解し抽出することが重要な課題として知られています(4)。
そこでMD研では、文書要約の技術を拡張したモデルを機械読解モデルと組み合わせることによって、説明型機械読解技術を確立しました(5)、(6)(図3)。文書要約技術ではテキスト中の重要な文を要約として抽出しますが、提案手法では回答のために重要な文を根拠文として抽出します。このニューラル根拠抽出モデルが根拠文を抽出すると同時にニューラル読解モデルが回答を発見することで、根拠が複数の文に分かれてしまうような難しい質問に対しても、回答・根拠双方を精度良く提示することを実現しています。本技術によって、英語Wikipedia記事への質問に対して回答とその根拠を出力する機械読解タスクHotpotQA(4)において、発表当時リーダーボードの1位を獲得することができました。
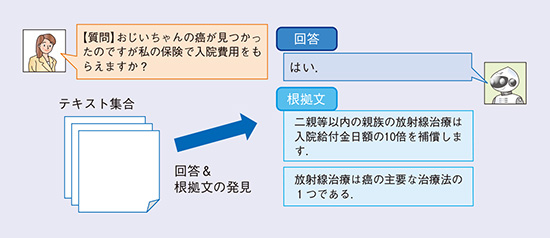
図3 説明型機械読解
質問があいまいな場合に問い返す「改定質問生成技術」
機械読解の研究用データセットでは回答が一意に特定できるように作成されたものが主流ですが、コンタクトセンタなどで実際にお客さまが入力する質問では、質問の意図があいまいで、回答を特定できない場合があります。このような場合に人間のオペレータのようにAIが適切に質問の意図を問い返すことができれば、より自然なコミュニケーションが実現できます。
そこでMD研では、あいまいな質問を機械読解が回答できる具体的な質問に書き換える改訂質問生成技術を確立しました(7)、(8)(図4)。提案手法では、質問に対する機械読解の回答の候補を抽出し、回答候補ごとに質問のあいまい性を解消した改訂質問を生成します。例えば、「弁護士特約の限度額はいくら」という質問をした際、改訂質問生成では、回答を直ちに提示するのではなく、「1回の事故による弁護士特約の保険金の限度額はいくら」と「法律相談・書類作成についての弁護士特約の限度額はいくら」といった複数の改訂質問を生成し、質問者に自身が聞きたいことに近い質問がどちらであるかを選択させるように問い返します。この例では、質問者が前者を選択した場合の回答は「300万円」、後者は「10万円」といったように、選択した改訂質問によって回答が変わります。これにより、従来よりも多様な質問に対して機械読解を適用することができます。
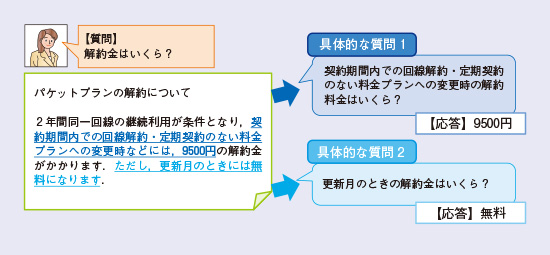
図4 改訂質問生成
スタイルを指定して回答を生成する「生成型機械読解技術」
現在の機械読解の問題設定は、回答を知識源となるテキストから抽出することが主流です。しかし、スマートデバイスやチャットボットでは、より自然な文章を生成することが求められます。しかし、回答の生成は難易度が高く、さらに学習データが不足しているため、これまで世界的に研究は進んでいませんでした。
そこでMD研では、テキストに書いていない表現を生成して応答可能な生成型機械読解技術を確立しました(9),(10)(図5)。例えば、「レッカー移動の受付時間は?」と質問した際に、「レッカー移動の受付時間は24時間365日です」のように、テキストのみでなく質問の内容を適切に含めた自然な応答を作成できることが特徴です。また、提案手法は、複数の異なる回答スタイルの機械読解データを同時に学習し、生成時に回答スタイルを選択できるようにしました。これにより、学習データが不足する問題を解決しています。提案手法は、検索エンジンの実ログを用いたオープンドメインなQAを行うMS MARCO(11)の回答スタイルの異なる2タスクにおいて、発表当時リーダーボードの1位を獲得することができました。

図5 生成型読解・回答要約
回答の長さを制御する「回答要約技術」
お客さまからの質問に応答するチャットボットにおいては、機械読解モデルが長い回答を出力した場合にそのまま提示するとお客さまが読み難いため、回答の長さを適切に調整することが望まれます。また、スマートフォンで回答を読む場合とPCで回答を読む場合など、状況に応じて回答の長さを適切に調整することで、よりお客さまや状況に合わせた柔軟な回答が可能になると考えられます。
そこでMD研では、ニューラルネットを用いて長さをコントロール可能な回答要約技術を確立しました(12)(図4)。本技術では、テキスト中の重要な個所を特定するニューラルネットのモデルと、特定した個所から回答を要約(生成)するニューラルネットのモデルを組み合わせることによって質問に対して適切に回答を要約する機能を実現しています。回答を要約する際に、長さの情報をベクトル化して与えることによって、任意の長さで回答を出力することが可能となります。
今後の展開
機械読解技術をコンタクトセンタにおけるマニュアルを対象とした質問応答に適用する中で実用化に向けた課題を発見し、さらに技術改善にフィードバックしていくことで、AIによるオペレータの支援、さらには、自動応対の実現をめざしていきます。機械読解は人間が用いる自然な言葉の理解という難しい挑戦であり、コンタクトセンタをはじめ、NTTグループのさまざまなエージェントAIサービスにおいてイノベーションを起こせると考えています。MD研では、人間と自然にコミュニケーションが可能なAIの実現をめざして、今後も研究開発に取り組みます。
■参考文献
(1) P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang:“SQuAD: 100,000+ questions for machine comprehension of text、”Proc. of EMNLP 2016, pp.2383-2392, Austin, U.S.A., Nov. 2016。
(2) 西田・斉藤・大塚・浅野・富田:“情報検索とのマルチタスク学習による大規模機械読解、”言語処理学会第24回年次大会、pp.963-966, 2018。
(3) K. Nishida, I. Saito, A. Otsuka, H. Asano, and J. Tomita:“Retrieve-and-read: Multi-task learning of information retrieval and reading comprehension、”Proc. of CIKM 2018, pp.647-656, Torino, Italy, Oct. 2018。
(4) Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning:“HotpotQA: A dataset for diverse, explainable multi-hop question answering、”Proc. of EMNLP 2018, pp.2369-2380, Brusseles, Belgium, Oct. 2018。
(5) 西田・西田・永田・大塚・斉藤・浅野・富田:“抽出型要約との同時学習による回答根拠を提示可能な機械読解、”言語処理学会第25回年次大会、pp.25-28, 2019。
(6) K. Nishida, K. Nishida, M. Nagata, I. Saito, A. Otuka, H. Asano, and J. Tomita:“Answering while Summarizing: Multi-task Learning for Multi-hop QA with Evidence Extraction、”arXiv, 1905.08511, 2019。
(7) A. Otsuka, K. Nishida, I. Saito, H. Asano, and J. Tomita:“Specific question generation for reading comprehension、”Proc. of AAAI 2019 Reasoning for Complex QA Workshop, Honolulu, U.S.A., Jan. 2019。
(8) 大塚・西田・斉藤・西田・浅野・富田:“問い返し可能な質問応答:読解と質問生成の同時学習モデル、”第11回データ工学と情報マネジメントに関するフォーラム、A3-3, 2019。
(9) K. Nishida, I. Saito, K. Nishida, K. Shinoda, A. Otsuka, H. Asano, and J. Tomita:“Multi-style generative reading comprehension、”arXiv, 1901.02262, 2019。
(10) 西田・斉藤・西田・篠田・大塚・浅野・富田:“回答スタイルを制御可能な生成型機械読解、”言語処理学会第25回年次大会、pp.17-20, 2019。
(11) P. Bajaj, D. Campos, N. Craswell, L. Deng, J. Gao, X. Liu, R. Majumder, A. McNamara, B. Mitra, T. Nguyen, M. Rosenberg, X. Song, A. Stoica, S. Tiwary, and T. Wang:“MS MARCO: A human generated machine reading comprehension dataset、”arXiv, 1611.09268v3, 2018。
(12) 斉藤・西田・大塚・西田・浅野・富田:“クエリ・出力長を考慮可能な文書要約モデル、”言語処理学会第25回年次大会、pp.497-500, 2019。

(後列左から)大塚 淳史/野本 済央/西田 京介
(前列左から)斉藤 いつみ/浅野 久子/西田 光甫
問い合わせ先
NTTメディアインテリジェンス研究所
知識メディアプロジェクト
TEL 046-859-2674
FAX 046-859-2116
E-mail kyosuke.nishida.rx@hco.ntt.co.jp



機械読解の研究を通じて学術的に世界で一番の技術を創るとともに、実社会の中でたくさんのお客さまの役に立つAIサービスの実現をめざして研究開発に取り組んでいきます。