2019年7月号
オペレータの応対を支援する自動知識支援システム
- コンタクトセンタAI
- 対話理解
- FAQ検索
近年、コンタクトセンタでは取り扱う商品やサービスの種類や複雑さが増大し、それに伴うオペレータに求められる知識量の増加はオペレータにとっては大きな負担となり、オペレータの定着率も低下しています。本稿では、特に業務経験の浅いオペレータを支援するために、応対中のオペレータに適切な情報(知識)を自動的に提示する自動知識支援システムを紹介します。
長谷川 隆明(はせがわ たかあき)/ 関口 裕一郎(せきぐち ゆういちろう)/ 山田 節夫(やまだ せつお)/ 田本 真詞(たもと まさふみ)
NTTメディアインテリジェンス研究所
コンタクトセンタの課題
コンタクトセンタは企業の顧客接点として重要な役割を担っています。短時間で適切に応対することによって顧客満足度を向上させることが大きな目標の1つとなっています。しかしながら、取り扱う商品やサービスの種類や複雑さは年々増大し、それに伴うオペレータに求められる知識量の増加はオペレータにとって大きな負担となり、オペレータの定着率も低下しています。このような状況の中で、特に業務経験の浅いオペレータを支援するために、応対中のオペレータに適切な情報(知識)を自動的に提示する自動知識支援システムを開発しています。
一方、オペレータに提示する情報(知識)の作成・維持には大きなコストがかかっています。これらのコストを下げるために、情報(知識)の1つであるFAQ(Frequent Asked Question)の整備を支援する技術にも取り組んでいます。本稿では自動知識支援システムおよびFAQ整備支援技術について紹介します。
自動知識支援システムの概要
自動知識支援システムは、コンタクトセンタ(コールセンタ)に電話をかけてきたお客さまの用件に基づいて適切な情報を応対中のオペレータに提示することで、業務経験の浅いオペレータを支援するシステムです。オペレータが閲覧・操作するシステムの画面を図1に示します。画面の左側にはオペレータとお客さまの発話がテキストとして表示され、画面の右側にはお客さまの用件を伝える発話あるいはオペレータの用件を確認する発話から自動で検索されたFAQからスコアの高い類似質問とその回答が表示されます。
本システムは以下のステップからなります。
① 音声対話のテキスト化:「話し終わり判定」により、オペレータとお客さまの音声対話を認識してオペレータが見やすいかたちでテキストにします。
② 音声対話の構造化:「応対シーン推定」により、コンタクトセンタの音声対話にみられる特徴から音声対話を構造化します。
③ FAQ検索の自動化:「FAQ検索発話判定」により、お客さまの用件を含む発話あるいはオペレータが用件を確認する発話を抽出し、それをFAQ検索のクエリとして利用することであらかじめ作成されたFAQを自動検索します。
音声認識から発話判定までの具体的な様子を図2に示します。
音声対話のテキスト化
音声をテキスト化するには、最初に音声認識技術を用いますが、音声認識の結果をそのまま表示するだけではオペレータとお客さまの2人の対話を見やすくすることはできません。お客さまは電話を掛ける際に考えながら用件を伝えるため、発話がゆっくりになったり、間が空いたり、つっかえたりします。そのため、お客さまの発話の音声認識結果をそのまま表示すると、ポーズが空いたところで区切れてしまい、本来は意味的にはひとまとまりにして表示するべき発話が分割され、分かりにくくなってしまいます。自動知識支援システムでは「話し終わり判定」という機能を実現し、比較的長い単位で発話を表示しています。本機能は、音声認識の結果を受けて、オペレータやお客さまが話し終わったかどうか、言いたいことを言い切ったかどうかを判定する機能です。1000通話程度の教師データからDNN(Deep Neural Network)によって学習されたモデルによる判定に加え、相手のあいづちを無視しながら、話者が変わる話者交代の時点で直前の話者は話し終わったとみなすヒューリスティックスによる補完を行うことで、高い判定精度を確保しています。
音声対話の構造化
コンタクトセンタの対話は、特定の商品に関する問合せや特定のサービスに対する手続きの依頼など、業務で扱うタスクに偏った対話であるため、対話の流れには典型的なパターンがみられます。例えば、ある保険商品に関する問合せを受け付けるコールセンタでは、オペレータによる自身の名前を名乗るあいさつから始まり、お客さまが電話をかけてきた用件を確認し、契約者や契約内容を確認したうえで、用件への対応を行い、最後にお礼を述べて対話が終了します。オペレータとお客さまの対話を理解するために、このような対話の流れを大局的につかむことは非常に重要な手掛かりとなります。私たちはこの対話の流れをつかむ機能を「応対シーン推定」と名付け、インバウンド型のコールセンタの応対シーンにふさわしいラベルを設計し、1000通話程度のコールセンタの対話ログから教師データを作成し、DNNによりモデルを学習することで、高い精度で応対シーンを推定する技術を確立しました。
FAQ検索の自動化
FAQを自動で検索するためには、検索のためのクエリを適切に選ぶことと、検索のタイミングを適切に計ることの2点を満たすことが重要になります。検索のクエリについては、音声認識の結果をそのまま用いるのではなく、前述の「話し終わり判定」の結果を利用することで発話の分断を防ぐことができ、発話のまとまった単位を検索のクエリとすることができます。例えば、図2の例にある「実は、今月末をもって引越しをすることになりまして、」という発話で分断されると、クエリとして「引越し」というキーワードだけで検索することになり、後に続く発話に含まれる「解約」や「住所変更」といったキーワードがなければオペレータにとって有効なFAQを検索することができません。このように「話し終わり判定」の結果を利用することで、発話から適切なクエリを選ぶことが可能になります。
また、お客さまやオペレータの発話があるたびに検索するのでは、検索の頻度が多くなり過ぎて、オペレータが検索結果を確認することが難しくなります。そこで、どの発話が用件であるのかを判定する必要があります。お客さまの発話が用件を述べているかどうかを判定する「用件発話判定」と、オペレータの発話が用件を確認している発話かどうかを判定する「用件確認発話判定」という局所的な分類機能を機械学習により実現しました。このときに、前述の大局的な「応対シーン推定」と組み合わせることによって、「問い合わせ把握のシーン」の発話だけに絞って「用件発話判定」と「用件確認発話判定」を適用しています。これによって、例えば「本人確認のシーン」の発話から誤って用件を抽出することがなくなるため、用件の抽出精度を向上させることが可能になりました。このようなプロセスで、用件として判定された発話から抽出したキーワードをクエリとすることで、FAQに対する適切な検索タイミングを実現しました。
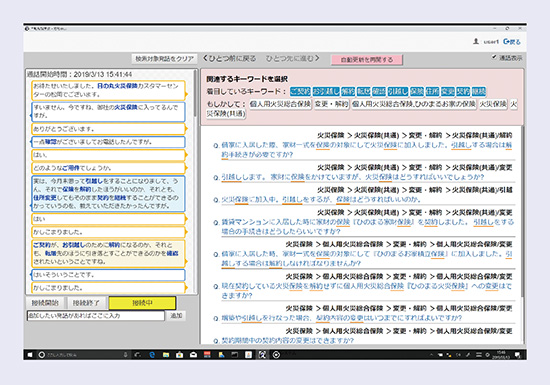
図1 自動知識支援画面
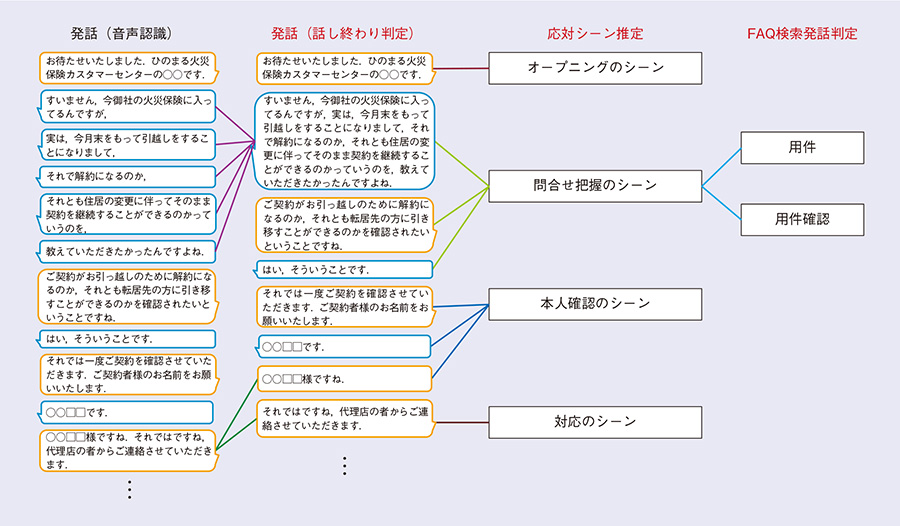
図2 自動知識支援のステップ
FAQの作成支援
用件発話もしくは用件確認発話からFAQ検索を行っても、それに対応するFAQが検索対象として整備されていなければ、適切な検索結果を返すことはできません。FAQは質問文と回答文から構成されますが、回答文についてはオペレータが不正確な応対をした場合のリスクが高いため、適用先コンタクトセンタの業務に精通したセンタ運用者が作成・整備する必要があります。
一方で質問文については実際にお客さまから聞かれる内容に基づいて作成する必要があるため、実際の応対においてよく聞かれる事柄である必要があります。コンタクトセンタに蓄積された過去の通話内容(応対ログ)を解析することにより、FAQとすべき高い頻度で聞かれている事柄を質問文の候補としてセンタ運用者に提示するFAQ整備支援技術を実現しました(図3)。
まず、応対ログの中から用件となる部分を上述の「用件発話判定」を用いて抽出します。お客さまから聞かれる用件は多種多様ですが、FAQに追加すべき用件は過去に複数回にわたって質問されているものであるため、得られた用件を集約し頻度の高いものに絞り込みます。その際には、含まれている語句を手掛かりに各用件を多次元ベクトル空間に落とし込み、似た用件どうしをクラスタリングする手法を用いています。その後、集約された用件集合のうち、一定以上の規模を持つものを選び出すことにより、質問文とすべき候補の提示を行います。
従来は自動知識支援システムの構築時に、作業者が大量の応対ログを確認して質問文の候補をセンタ運用者に伝えていましたが、この部分を自動化することによりシステム導入コストの低減に貢献します。
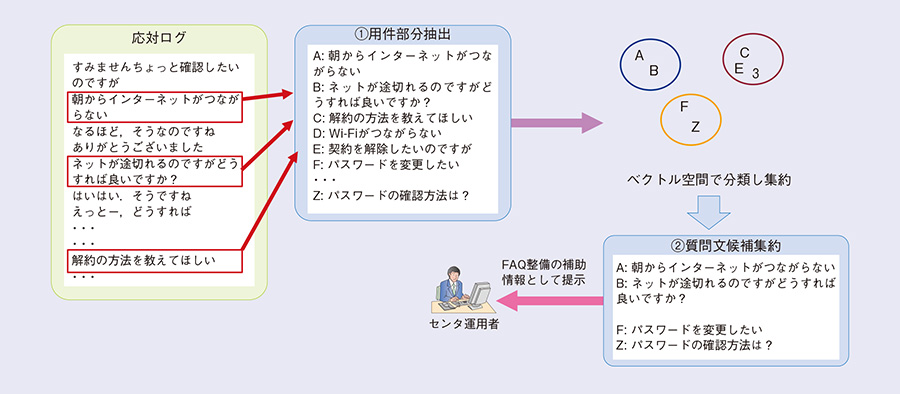
図3 FAQ整備支援技術
今後の展開
本稿では、コンタクトセンタにおけるオペレータとお客さまの対話から用件を抽出しFAQを検索する技術を紹介しました。紹介した機能の多くは機械学習により実現されているため、本システムの導入にあたっては、コンタクトセンタごとに大量の教師データを低コストで作成したり、すでに作成されたモデルをさまざまなタスクに適用できるように汎用化することが重要な課題です。
今後もFAQの精度向上に加えて、導入コストの削減の課題に対しても継続して取り組んでいきます。

(左から)山田 節夫/関口 裕一郎/長谷川 隆明/田本 真詞
問い合わせ先
NTTメディアインテリジェンス研究所
知識メディアプロジェクト
E-mail keicho-ml@hco.ntt.co.jp



人と人の自然な音声対話を理解したり背景知識を必要とするドキュメントを理解することは非常に難しいのですが、コンタクトセンタのようにタスクを限定すれば音声対話を理解したり文書を検索することで経験の浅いオペレータを支援できるようになってきました。今後はもっとオペレータを支援できるレベルを上げていきたいと考えています。