2020年10月号
特集
顧客接点業務を支援・代替する知識・ 言語処理技術
- AI
- 文書要約
- 応対分析
NTTメディアインテリジェンス研究所では、長年培ってきた自然言語処理技術をコアコンピタンスの1つとして、コンタクトセンタやオフィスの生産性向上に資する知識・言語処理技術を研究開発しています。本稿では、現在取り組んでいる技術のうち、言語モデル・文書要約技術・応対分析技術について紹介します。
西田 京介(にしだ きょうすけ) / 齋藤 邦子(さいとう くにこ)
甘粕 哲郎(あまかす てつお) / 磯 和之(いそ かずゆき)
西岡 秀一(にしおか しゅういち)
NTTメディアインテリジェンス研究所
はじめに
NTTメディアインテリジェンス研究所では、コンタクトセンタ向け技術として、業務マニュアルやFAQなどの文書を解析し、お客さまに応対するオペレータへ適切な文書を提示する知識・言語処理技術を研究開発してきました。昨今、コンタクトセンタだけでなくオフィスにおいても、オペレータ・社員のさらなる生産性向上に関するニーズがあることから、大規模な文書や多様な応対を理解・生成する技術に取り組んでいます。以下に、文書を扱うための言語モデルと、その言語モデルを用いた文書要約技術について説明した後、お客さまとオペレータ間の応対に関する分析技術について述べます。
言語モデルBERTによる自然言語理解の発展
AI(人工知能)が人間の言葉を理解することはこれまで難しいとされてきました。しかし、2018年10月にGoogleが発表したBERT(1)の出現により、自然言語理解の研究開発には大きなパラダイムシフトが発生しました。例えば、機械読解という、テキストの内容を理解して質問に回答する「文章読解力」が求められるタスク(2)においては、BERTを利用したAIにより人間の回答スコアを大きく上回った例も報告されています。機械読解以外の自然言語処理タスクにおいても性能が大幅に改善しており、言語モデルはAIの言語理解能力の実現に関する基盤技術として注目が集まっています。
言語モデルとは、文章のもっともらしさを推定するモデルです(図1)。例えば、「今日は誕生日なので○○を食べた」という文章の○○の部分については「ケーキ」のほうが「卵」よりも自然と感じる方が多いと思います。また、「今日はいい天気だ」と「洗濯日和だ」の2文が連続して出現するのは自然に感じられるでしょう。BERTは、このような単語の穴埋め問題(単語の予測)と、連続する2文間の関係性判断(次の文であるかの予測)をWikipediaのすべての文章など大量のテキスト集合を基に事前学習しています。こうして得られた言語モデルBERTをベースとして、さまざまなタスク依存のデータセットで学習(Fine-tuning)することにより、テキストをジャンルごとに分類するタスク、質問の回答となるフレーズを抜き出すタスク、などのさまざまな応用タスクに適用でき、さらに応用タスクでの学習データが多く得られない場合においても高い性能を実現できるようになりました。
BERTは自然言語処理の研究分野に大きな衝撃を与え、現在も世界中にて言語モデルの構築・活用の研究が行われています。NTTメディアインテリジェンス研究所では、日本語のテキストデータを大量に収集して日本語のBERTを作成するとともに、言語モデルを文書要約(3)、(4)、文書検索(5)、質問応答(6)、(7)などのタスクにおいて活用する技術を研究しています。いずれも単純にBERTを適用するのではなく、これまでの自然言語処理および深層学習の研究により得られた知見を活かすことで、高い性能を実現しています。また、BERTの特性・内部動作について調査(8)することで、BERTの欠点を改善したNTT独自の言語モデルの構築をめざして研究を進めています。

長さを指定して文書を要約する「文書要約技術」
先ほどの言語モデルを活用した技術の代表例として文書要約技術を紹介します。文書要約は古くから取り組まれてきた技術分野ですが、コンタクトセンタなどにおける顧客接点業務においては、 お客さまからの質問に対してAIが検索・質問応答の結果として長い文章を返却するとお客さまが読み難いため、文章の「長さ」を適切に調整することが望まれます。
そこでNTTメディアインテリジェンス研究所では、ニューラルネットを用いて長さをコントロール可能な文書要約技術を確立しました(3)。私たちのモデルは、文章中の重要な個所を特定する抽出モデルと、元の文章から要約文を生成する生成モデルとを組み合わせた構成になっており、抽出モデルは言語モデルをベースに学習しています。指定した長さに応じて抽出モデルが出力する重要な単語の個数を制御し、この重要語と元文を両方考慮して要約文を生成することで、長さを制御可能でかつ高い精度で要約可能なモデルを実現しました。
NTTメディアインテリジェンス研究所で確立した文書要約技術は、NTTコミュニケーションズで展開するCOTOHA®API要約機能のコアエンジンとして活用されています(9)。文書を入力すると要約文書を出力するサービスがCOTOHA Summarizeとして提供開始されており、ご契約いただいたお客さまには、Webブラウザで閲覧したサイトの要約文を生成するツールも無償で提供されています(10)。今後、NTTグループへの技術展開をさらに進めていく予定です。
加えて、文書要約だけではなく対話をターゲットとした要約技術、要約の観点やキーワードを外部から指定可能な要約技術など、要約技術の高度化に向けて研究開発を進めていきます。また、言語モデルのさらなる競争力強化をめざして、モデルの大規模化、また、より自然な文を生成するための生成型言語モデルの構築とこれに基づく要約技術の確立(4)など、最新の言語処理研究の成果を取り入れながら技術開発を進める予定です。
コンタクトセンタの通話からの知見を活かすための技術
顧客接点の支援での課題
これまで、NTTメディアインテリジェンス研究所では、「自動知識支援システム」(11)を開発してきました。これは、お客さまとの会話の内容に応じた文書を自動的に検索し、提示する技術です。オペレータを知識面で支援するとともに、適切な情報で速やかに応対することで、お客さまとの関係性も向上させるものでした。
一方、オフィスDX(デジタルトランスフォーメーション)や新型コロナウイルス感染症流行によるビジネススタイルの変化に伴い、コンタクトセンタには新たな役割が求められています。その1つが、インサイドセールスと呼ばれる営業手法での役割です。インサイドセールスとは、これまでの専任の営業員が対面営業でニーズの汲み取りや商談の成約まで行う手法に対し、ニーズ把握など商談のきっかけとなる情報のヒアリングを、電話やWeb会議で行いながら相手と継続なコミュニケーションを維持し、受注・契約の可能性が高まったところで営業員を派遣する手法です。この手法によるお客さまとの対応を担うコンタクトセンタが増えています。
この役割におけるコンタクトセンタの課題としては以下のようなものがあります。
・オペレータの生産性の一層の向上:応対後の報告作成について、会話の流れが複雑で話題も多岐にわたる商談の中から、応対で重要だった情報を取り出し集約するための支援が必要となります。
・営業情報分析の生産性向上:オペレータを統括する立場では、各オペレータが実施するお客さまとの商談に含まれる成約の見込み、お客さまニーズの傾向、その他会話の傾向を把握・分析します。分析した情報から、計画やオペレータの業務を改善します。そうした分析、改善業務も支援する必要があります。
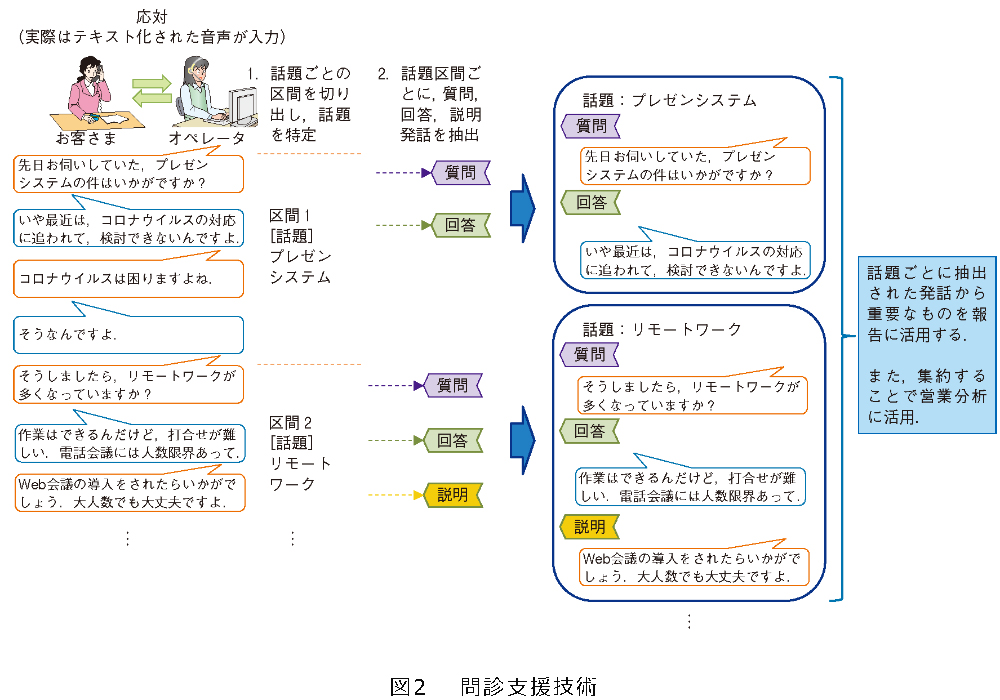
問診支援技術
上記の課題を解決するために私たちは「問診支援技術」を開発しました。
本技術は、2つの要素からなります(図2)。1つは、お客さまとの一連の応対内容を話題ごとの区間に特定する技術です。もう1つは、前者で特定した区間から質問、回答、説明といった重要な発話を抽出する技術です。
お客さまの課題や要望を引き出すための営業会話では、お客さまの回答に応じて話題が次々と変化するという特徴があります。これまでの技術ではそのようなダイナミックな状況に対応できなかったため、まず話題の変化点をしっかりとらえることにしました。これが1番目の技術の特徴です。会話に現れる話題の変化点に特徴的な表現を利用した機械学習により、同じ話題の区間を特定し、話題に特徴的な表現を利用した機械学習により話題の種別を取得しています。次に、2番目の技術の特徴としては、質問や回答など重要な発話に含まれる特徴的な表現を利用した機械学習により、話題ごとにオペレータやお客さまの質問や回答の発話を抽出します。
オペレータは、本技術による話題ごとに区間で分割された通話テキストを用いることで、通話終了後、お客さまのニーズや予算などについて聞き出した個所をすばやく見つけ出し、報告書の作成ができます。また、多くの通話からこれらの情報を集約することで、営業情報の分析の支援が可能となります。
これらの技術は音声での応対だけでなく、最近増えているチャットによるコンタクトセンタへの適用もめざしています。
おわりに
今後、大規模な文書や多様な応対を理解・生成する技術として、多様な文書レイアウトを読み解き、必要な情報を高速・高精度に探索可能とする技術や、より詳細に会話内容を把握し、お客さまも気が付きにくいニーズなどを掘り起こす、戦略的な会話をサポートする技術に取り組む方針です。
■参考文献
(1)J. Devlin, M. W. Chang, K. Lee, and K. Toutanova: “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,”NAACL-HLT (1), pp. 4171-4186, 2019.
(2)西田・斉藤・大塚・西田・野本・浅野:“機械読解による自然言語理解への挑戦,”NTT技術ジャーナル,Vol. 31, No. 7, pp. 12-15,2019.
(3)斉藤・西田・西田・大塚・浅野・富田・進藤・松本:“出力長制御と重要箇所の特定を同時に行う生成型要約,”2020年度人工知能学会全国大会,2020.
(4)斉藤・西田・西田・浅野・富田:“事前学習済Sequence-to-Sequence モデルと重要度モデルの結合による生成型要約,”言語処理学会第26回年次大会, pp. 4-29, 2020.
(5)長谷川・西田・加来・富田:“高速な情報検索に向けた文脈考慮型スパース文書ベクトルの獲得,” 2020年度人工知能学会全国大会, 2020.
(6) K. Nishida, K. Nishida, I. Saito, H. Asano, and J. Tomita :“Unsupervised Domain Adaptation of Language Models for Reading Comprehension,”LREC, pp. 5392-5399, May 2020.
(7)西田・西田・斉藤・浅野・富田:“回答の根拠を解釈可能な機械読解,”言語処理学会第26回年次大会, pp. 1-19, 2020.
(8)大杉・斉藤・西田・浅野・富田:“マスク化言語モデルと系列長に関する分析,”2020年度人工知能学会全国大会, 2020.
(9)https://api.ce-cotoha.com/contents/index.html
(10)https://www.ntt.com/about-us/press-releases/news/article/2020/0423.html
(11)長谷川・関口・山田・田本“オペレータの応対を支援する自動知識支援システム,”NTT技術ジャーナル,Vol. 31,No. 7,pp. 16-19, 2019.

(左から)
西田 京介/甘粕 哲郎/西岡 秀一/磯 和之/齋藤 邦子
問い合わせ先
NTTメディアインテリジェンス研究所
社会知識処理プロジェクト
E-mail ai-p-ml@hco.ntt.co.jp



オフィス業務の生産性向上を実現するため、企業活動において常に生成・蓄積されている文書・応対ログなどから、知識を抽出・活用する知識・言語処理技術の研究開発に取り組んでいきます。