2026年6月号
特集
業務固有の知識を活かすAIエージェントのビジネス適用――実践事例から見るドメイン特化型アプローチの価値と展望
- AIエージェント
- ノーコードデータ分析
- 行動変容
NTTドコモビジネスは、業務固有の知識を活かしたドメイン特化型AI(人工知能)エージェントの開発・展開を推進しています。本稿では、ノーコード時系列データ分析ツール「Node-AI」の活用支援をビジネスケースとして、データ分析のノウハウや実データ情報を組み込んだエージェントを開発した実践事例を紹介します。岩手大学での適用評価においてユーザの探索的分析行動の向上が確認され、ドメイン知識の組み込みがビジネス価値の向上に有効であることを示します。
南葉 潤一(なんば じゅんいち)
NTTドコモビジネス
NTTドコモビジネスが取り組むAIエージェントについて
生成AI(人工知能)*1の急速な普及を背景に、業務を自律的に実行するAIエージェント*2への期待が高まっています。NTTドコモビジネスは、こうした潮流をいち早くとらえ、顧客体験、従業員体験、セキュリティ運用の3領域にわたるAIエージェントの開発・提供を推進しています。
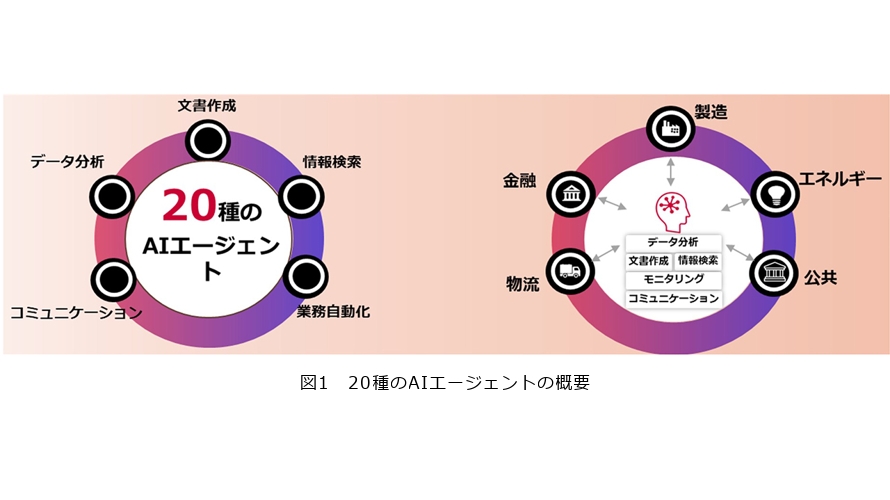
その取り組みの一環として、2025年6月、AIプラットフォーム「exaBase Studio」を展開する株式会社エクサウィザーズとの資本業務提携を通じて、文書作成・データ分析・情報検索・業務自動化・コミュニケーションの5カテゴリにまたがる20種のAIエージェント(図1)の提供を開始しました(1)。製造業向け知財文書作成支援、特定業界向け資料作成支援など、業界特化型エージェントの実績も着実に積み重ねています。
これらに共通するアプローチは、汎用AIでは対応が難しい業務固有の知識をエージェントに組み込み、現場の課題を解決するという設計思想です。将来的には200種への拡充をめざし、汎用型と業界特化型の両軸で開発を継続しています。
本稿では、こうした取り組みの一例として、ノーコード時系列データ分析ツールの活用支援を目的とした対話型AIアシスタント機能における、ドメイン特化型AIエージェント適用実践について紹介します。
*1 生成AI:大規模言語モデルを用い、テキスト・画像・音声などのコンテンツを生成するAI技術の総称。
*2 AIエージェント:生成AIを中核に、外部ツール連携・記憶・役割定義を組み合わせ、目標に向けて自律的に行動するソフトウェアシステム。
ビジネスケースへの適用例:ノーコード時系列データ分析ツール「Node-AI」の活用支援
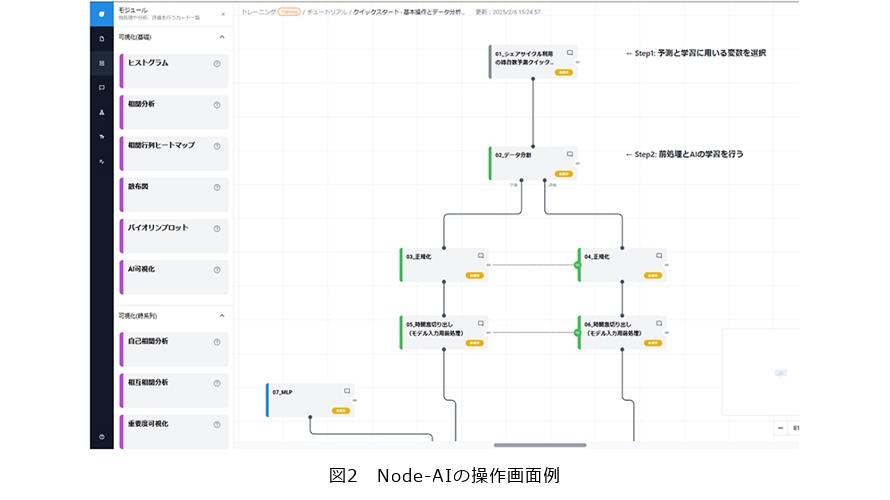
Node-AIは、NTTドコモビジネスが提供するSaaS(Software as a Service)型のノーコードデータ分析プラットフォームです(2)。ブラウザ上でカードをドラッグ&ドロップで接続するだけで、プログラミング不要で時系列データの予測・異常検知用のAIモデルを構築することができます(図2)。AIモデルの予測に寄与する入力を可視化する要因分析機能や、NTT研究所が開発した高速スパースモデリング手法FastSGL*3など、NTTグループの最先端の研究開発成果をプロダクトに実装した独自機能を備えています。製造・小売・エネルギー・インフラなど幅広い業界における需要予測・機器予防保全・品質管理等に活用されており、「第16回ASPIC IoT・AI・クラウドアワード2022」のAI部門総合グランプリを受賞(3)するなど、実用性が高く評価されています。
しかし、ノーコードという設計はプログラミングの技術的障壁を大幅に下げるものの、ツールや専門領域に固有のドメイン知識の習熟という壁は依然として残ります。これは専門性の高いツール全般に共通する課題であり、データ分析の領域においては特に、「何をどのように分析すべきか」という方針の立案が、技術的なモデル構築と同等かそれ以上に重要となります。この判断にはツールの操作手順はもとより、どのデータをどの分析モジュールに投入すべきかといったデータ分析プロセス全体への深い理解と、場合によっては専門家による個別の伴走支援が求められます。Node-AIのようなツールが技術的参入障壁を下げたことで、こうしたドメイン固有の知識こそが、分析の質と継続性を左右する本質的な課題として顕在化しました。
そこでNTTドコモビジネスでは、Node-AIの操作手順やデータ分析プロセスのノウハウを体系的に埋め込んだドメイン特化型AIエージェントを開発しました。実際の分析対象データの文脈も踏まえた応答が可能なため、ユーザは専門知識を事前に習得しなくとも、AIとの対話を通じて分析を進めることができます。人手による個別支援への依存を低減しながらサービス価値を維持するこの取り組みについて、その設計と実践を次に紹介します。
*3 FastSGL:NTTコンピュータ&データサイエンス研究所が開発した手法で、通常のSGL(Sparse Group Lasso)と比較して学習速度が高速であることが特長。
ドメイン特化型マルチエージェントの設計と適用
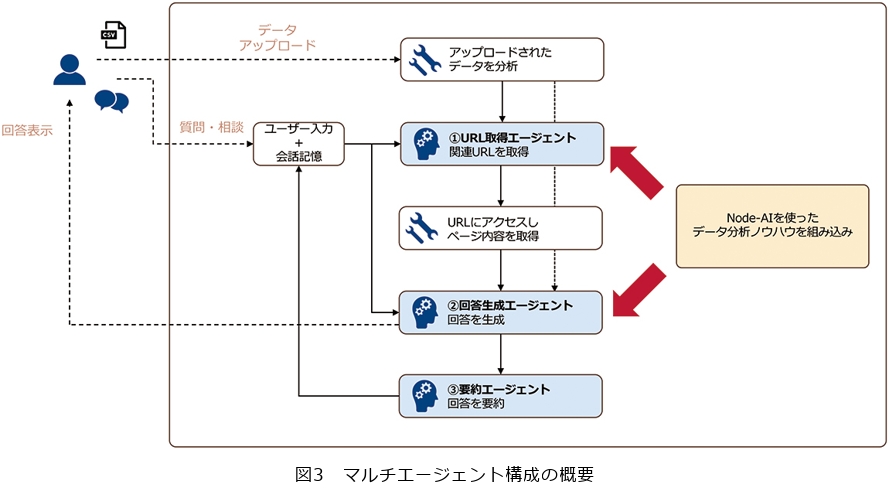
■マルチエージェント構成の概要
本システムは3つのAIエージェントが連携するマルチエージェント構成を採用しています(図3)。①URL取得エージェントは、Node-AIのウェブマニュアル群の中から状況に応じて関連性の高いページをリストアップします。②回答生成エージェントは、選択されたマニュアルページの全文と実データの情報を組み合わせ、具体的な分析手順を生成してユーザに提示します。③要約エージェントは、回答生成エージェントが出力した応答の要点を保ちつつ圧縮し、次のターン以降の会話記憶として再格納します。この3エージェント構成により、役割の分離と処理の効率化を両立しています。
加えて、本システムの特長は、これまでの伴走支援を通じて蓄積してきたノウハウを各エージェントの動作に組み込むことで、データ分析ドメイン特化を実現している点にあります。
■マルチエージェント構成を採用した理由
本システムの設計にあたってまず検討したのが、RAG(Retrieval-Augmented Generation:検索拡張生成)を用いる一般的なアーキテクチャです。RAGはドキュメントをチャンク(小断片)に分割してベクトルデータベースに格納し、ユーザの質問と意味的に近いチャンクを検索して回答に活用する手法です。しかしNode-AIのマニュアル体系は、個々のページが独立した機能を解説しながらも、「データ読み込み→前処理→モデル学習→評価→可視化」という分析フロー上で有機的に関連しています。チャンキングによってページを断片化すると、このページ間の文脈的つながりが失われ、分析の全体像をユーザへ正確に伝えることが困難になります。そこで本システムでは、ページ単位での全文取得を前提とした2段階構成、すなわちURL取得エージェントが関連ページを選択し、回答生成エージェントがその全文を読み込んで回答を生成するという分業構造を選択しました。
エージェントを役割ごとに分離することは、保守性の観点でも利点があります。ノウハウの更新やマニュアル構成の変更が生じた際、影響を受けるエージェントだけを修正すればよく、システム全体の再調整が不要です。また、要約エージェントを専任で設けることで、会話ターンが積み重なってもコンテキストが肥大化しないよう記憶を圧縮・管理でき、長期的な対話においても安定した動作を維持できます。
■Node-AIの分析ノウハウを組み込む仕組み
URL取得エージェントは、ユーザの入力とそれまでの会話記憶に加え、ユーザがアップロードしたデータの列名・データ型・サンプル値といった構造や特徴量の情報も踏まえたうえで、関連性の高いマニュアルページを選択します。関連ページの特定にはベクトル類似度の計算ではなく生成AIの推論を用いており、マニュアルのURL一覧と各ページの説明テキストを参照しながら、ユーザが何を達成しようとしているかを文脈的に判断してページを選択します。
この際、エージェントの動作には、Node-AIによる分析の標準的な進め方や判断基準、初学者が陥りやすいポイントといった、これまでの伴走支援を通じて蓄積してきたノウハウが組み込まれています。例えば、「異常検知をしたい」というユーザの一言に対して、単に異常検知の概要ページを返すのではなく、モデル選定・前処理・異常度可視化など、分析完遂に必要な複数の関連ページを的確に選択するよう設計されています。
■実データを文脈として活用する仕組み
回答生成エージェントは、URL取得エージェントが選択したマニュアルページの内容と実際のデータ情報を組み合わせ、ユーザの手元のデータに即した具体的な回答を生成します。これにより、「このデータは列数が多いため、まず相関分析で特徴量の絞り込みを行うことを推奨」「このデータは長期にわたる時系列パターンを持つため、LightGBM*4よりInformer*5が適している」といった、汎用的な手順案内ではない、データ固有のアドバイスを行うことが可能です。
*4 LightGBM:Microsoft社が開発した、高速な決定木学習アルゴリズム。
*5 Informer:Transformerベースの長期時系列予測モデル。半と同ペースで発見が続いていることを意味します。
■長期的な対話における記憶管理の仕組み
要約エージェントは、各ターンの終了後に回答の要点を圧縮して記憶として置き換えます。これにより、会話が長期化した場合でも「これまでに何を行ったか」という文脈を適切に引き継ぎながら、動作の安定性を維持することが可能です。さらに、ユーザの質問が「次は何をすればいいですか?」のようにあいまいな場合でも、会話記憶とデータの文脈を組み合わせた推論によって適切なマニュアルを選択することができ、ユーザとエージェントの対話がスムーズに進むよう設計されています。
ユーザへの提供価値の評価
■適用事例:岩手大学におけるデータサイエンス実践演習
ドメイン特化型AIエージェントが、実際のユーザの分析行動にどのような効果をもたらすかを検証するため、Node-AIを用いた教育プログラムへの適用事例を取り上げます。
NTTドコモビジネスでは国立大学法人 岩手大学(岩手大学)の喜多教授、澤井教授のご協力のもと、地域産業の課題をデータ活用で解決できる次世代AI人材を育てるため、2024年度から教育プログラムを実施しています(4)。本プログラムでは、情報系を専門としない農学部生でもNode-AIを用いたIoT(Internet of Things)データ分析を実践的に学ぶことができます。そして、学生自身の専門領域にかかわる実データを分析対象とすることで、データ分析を自らの課題としてとらえる深い学びを促す設計となっています。
この教育プログラムの実践演習を、本AIエージェントの効果を定量的に評価する場としても活用しました(5)。具体的には、養鶏施設のIoTセンサから取得したデータ(温度・湿度・CO2濃度・日齢・斃死数等)を題材とする分析実習を2年間にわたり実施し、2024年度には汎用生成AIチャットボットを、2025年度には本稿で紹介したドメイン特化型AIエージェントをそれぞれ導入して、両者が学生の分析行動に与える影響を比較しました。
以降では、2024年度の汎用チャットボット利用群(チャットボット群)と2025年度のドメイン特化型AIエージェント利用群(AIエージェント群)を比較し、AIの違いが学生の分析行動に与えた影響を3つの観点から紹介します。
■ログ分析結果
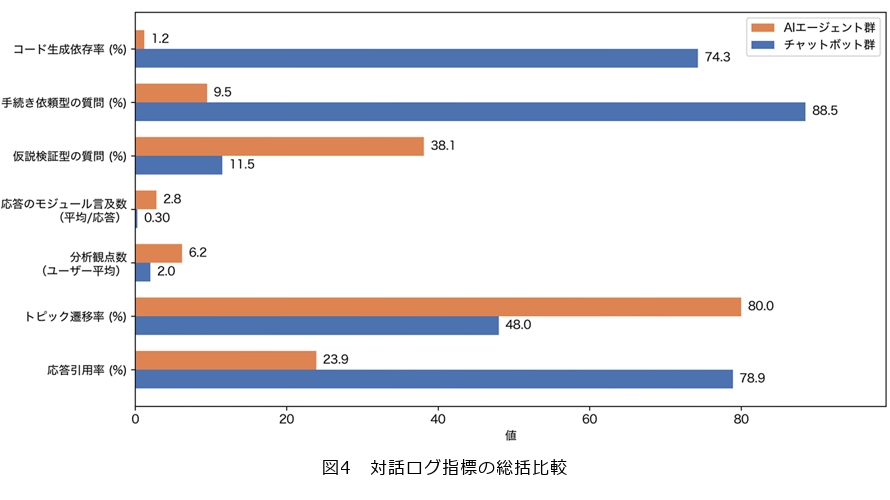
(1) AIへのプロンプトの性質が変化
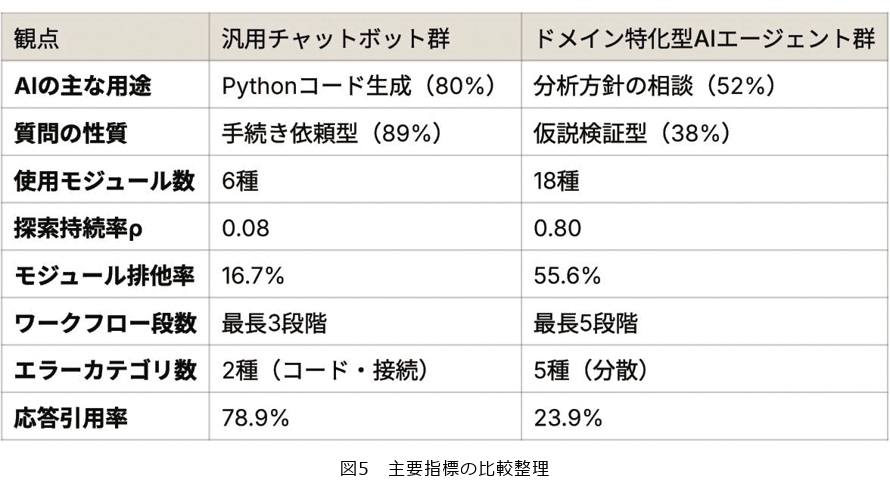
もっとも顕著な差異は、AIへのプロンプトの性質に現れました(図4)。チャットボット群では、プロンプトの約8割がPythonコードの生成依頼でした。チャットボットはNode-AI固有の操作体系を知らないため、学生がAIに依頼できる作業はデータ加工のためのコード生成に限定されていました。一方、AIエージェント群ではコード生成はほとんど見られず、最多は分析方針・戦略の相談で約半数を占めていました。
さらにプロンプトの形式を分類すると、チャットボット群は大半が「〜をつくってください」といった手続き依頼型であったのに対し、AIエージェント群では「〜は斃死数に寄与するか?」「〜によってリスクは変わるか?」といった仮説検証型が約4割を占めており、学生自身が判断しながら分析を進めていたことが示唆されます。
(2) 使用モジュールの多様性が3倍に拡大
次に、Node-AI上で実際に使用された分析モジュール(Node-AIが提供する個々の分析機能)の多様性を比較しました(図5)。チャットボット群が使用したモジュールは6種であったのに対し、AIエージェント群ではその3倍の18種に達しました。
ワークフロー段数も最長3段階から最長5段階へ増加し、データ→前処理→学習→評価→可視化という機械学習の全工程を踏んだグループが出現しました。さらに、グループ間のモジュール排他率(特定グループにだけ使用されたモジュールの割合)はAIエージェント群がチャットボット群を大きく上回り、各グループが同一データ・同一ツールを使いながらも異なる分析戦略を展開したことが示されました。
(3) 新たな分析モジュールの発見が終盤まで持続
モジュール多様性の差は、時間的な探索パターンにも表れました(図5)。チャットボット群では、分析の前半でモジュール発見がほぼ完了し、4グループ中3グループで後半の新規モジュール発見数がゼロとなりました。一方、AIエージェント群では全5グループが分析の後半も新規モジュールを導入し続けました。
この探索の持続性を定量化した指標が探索持続率ρ*6(分析の後半の新規モジュール発見数÷前半の発見数)です。チャットボット群のρは0.08であり、後半に既知モジュールの反復利用が大部分を占めていた一方、AIエージェント群ではρが0.80と約10倍の差がみられました。AIエージェントが分析の進行状況に応じて次に試すべきモジュールを提案できることが、この探索の持続に寄与したと考えられます。
*6 探索持続率ρ:ρ=0なら後半で新規モジュールの発見がなく探索が収束し、ρ=1なら前半と同ペースで発見が続いていることを意味します。
■ユーザの行動変容
定量分析に加え、実際の対話ログの比較から、行動変容の質的側面も確認しました。
チャットボット群の対話はコード生成を依頼し、受け取り、修正を依頼するという反復パターンに収束しており、分析の方向性は学生自身が別途決定し、AIの出力をNode-AIに貼り付ける使い方に終始していました。
AIエージェント群では、データの特性に基づく仮説をAIに投げかける探索的な対話が展開されました。例えば、「日内温度差がその日以降の斃死数に影響を与えるか調べたい。斃死数の日にちをずらして相関を取りたい」「幼鶏期にCO2が中央値より高かった場合にその後の斃死数が増加するか可視化したい」といったプロンプトが確認されました。学生が仮説を立て、検証方法をAIに相談し、結果を踏まえて次の仮説へと進む対話サイクルが成立していたと考えられます。
■ユーザへの提供価値のポイント
以上の結果から、ドメイン特化型AIエージェントの提供価値は分析作業の効率化にとどまらず、分析の探索性と主体性の向上にあることが明らかになりました。
汎用チャットボットはNode-AIの操作体系を把握していないため、ツールとコードの橋渡し役として機能するにとどまり、ユーザの分析行動の幅は限定的でした。これに対し、ドメイン特化型AIエージェントはNode-AIのモジュール体系と実データの特性を踏まえた応答が可能なため、ユーザは何をどう分析するかという本質的な問いに集中できました。その結果、AIとの対話を通じて仮説を具体化し、多様なモジュールを自律的に試行する行動変容が生じました。
こうした効果は、地域産業の課題解決において特に意義があります。情報系を専門としない農学部生が、AIエージェントとの対話を通じて養鶏データの分析を自律的に進められるようになるという本事例の成果から、AIの専門家でなくとも専門知識とデータ活用を組み合わせて地域課題に取り組めるAI人材の育成モデルとして、一次産業をはじめとする地域産業への貢献が期待されます。
ノーコードツールとAIエージェントを組み合わせた本事例のアプローチは、データ分析の専門知識習得における障壁を実質的に低減し、より多くのユーザが高度な分析を自律的に行える環境の実現と、サービス価値の向上に貢献するものと考えます。
今後の展望
本稿では、ノーコード時系列データ分析ツールの活用支援というビジネスケースにおける、ドメイン特化型AIエージェントの適用実践について紹介しました。NTTドコモビジネスが展開する多様なAIエージェントの取り組みの一例として、特定のツールと業務に特化した知識をエージェントに体系的に埋め込むことで、ユーザの探索的な分析行動を引き出し、ビジネス価値を創出できることを示しました。
Node-AI活用支援においては、引き続きいくつかのチャレンジに取り組みます。今回のAIエージェントが「専門知識の壁」の低減に取り組んだのに対し、分析結果をビジネスアクションに結びつける「結果解釈の壁」への対応が次の課題です。定量的な分析結果を事業文脈で解釈し、具体的なアクションを提案する支援へと対応範囲を拡張することで、さらなるビジネス価値の向上をめざします。
より広い視点では、今回の事例で得られた設計・実践知見を他のビジネスケースへ横展開し、ドメイン特化型AIエージェントが生み出す価値を多様な業務領域で検証・拡大していきます。
■参考文献
(1) https://www.ntt.com/about-us/press-releases/news/article/2025/0619.html
(2) https://nodeai.io/
(3) https://www.aspicjapan.org/event/award/16/index.html
(4) https://www.ntt.com/about-us/area-info/article/20241105.html?msockid=1dc9de27ec4965802d13c8d8ed7f64dc
(5) 丹野・宇野・杉本・更科・石山・切通:“農学系大学生への生成AI・ノーコードツール活用によるデータサイエンス教育の実践,”日本教育工学会 2026年春季全国大会,2026.

南葉 潤一






今後もNTTドコモビジネスは、発展を続けるAIエージェントを活用してユーザの行動変容を促し、ビジネス価値を生み出すために、現場起点での開発と実践を推進していきます。ご興味がある方はぜひお気軽にお問い合わせください。