2023年10月号
特集1
障害に強いロバストネットワーク実現のためのNW-AI自己進化フレームワーク
- AIの自己進化
- カオスエンジニアリング
- デジタルツイン
NTT研究所では、ネットワーク障害の早期復旧のためにAI(人工知能)を用いたゼロタッチオペレーションの研究開発に注力しています。AIを用いたネットワークオペレーションを実現するためには、大量のネットワーク障害データを学習することが必要となります。私たちは、疑似環境の中で大量のネットワーク障害を人為的に生成し、それらへの対応方法を学習させることで、AIを自律的に学習させるフレームワークを確立しました。本稿では、提案フレームワークのコンセプトとフレームワークの中でAIがどのように学習していくかを解説しています。
高橋 洋介(たかはし ようすけ)/池内 光希(いけうち ひろき)
渡邉 暁(わたなべ あきお)
NTTネットワークサービスシステム研究所
はじめに
NTT研究所は、予期せぬ障害に強いロバストネットワークの実現をめざしています。この目標を達成するために、私たちはネットワーク運用業務の自動化に取り組み、AIを活用したゼロタッチオペレーションの研究開発を進めています。この取り組みの中心には、私たちがNW-AIと呼んでいる、ネットワークの運用を担うAI(人工知能)があります。
ゼロタッチオペレーションでは、人間の介入を最小限に抑え、NW-AIがネットワークの運用と管理を行います。具体的には、NW-AIは異常検知や障害個所の推定といったタスクを自動で実施します。例えば、NW-AIはネットワークにおける通信パターンやパフォーマンスデータを監視し、ネットワークの異常を検知することができます。また、障害が発生した場合、NW-AIはネットワークのトポロジ情報と膨大なログデータを分析することで、その原因となる個所を推定することができます。
このような取り組みの中で、特に難易度が高い課題として、NW-AIによるネットワーク障害の自動復旧が挙げられます。ネットワーク障害の自動復旧は、ネットワークの安定性とサービスの品質を保つために重要な要素であり、その実現はゼロタッチオペレーションの成功にとって不可欠です。
NW-AIによる自動復旧を実現するためには、NW-AIが障害時のパフォーマンスデータやログデータを大量に学習することが必要となります。これにより、NW-AIはさまざまな障害シナリオに対応する能力を獲得し、障害が発生した際に迅速かつ効率的に対応することが可能となります。
しかし、一般的な運用範囲を逸脱した条件下で発生する想定外障害については発生頻度が低いため、十分なデータを収集することが困難であり、その結果、NW-AIにこれらの障害への対応を適切に学習させることは難しいという問題があります。想定外障害は復旧手順が確立されていないため、復旧に長い時間がかかり、ユーザに深刻な影響を及ぼす可能性があります。想定外障害は一般的な運用範囲を逸脱した条件下で発生しますが、人力でこのような発生条件を探索するには莫大な時間と労力がかかるため現実的ではありません。
NTT研究所では、このような課題に対応するために「検証と運用の連携高度化」を実現する研究開発に取り組んでいます。具体的には、ネットワークのデジタルツイン環境と人為的な障害生成を可能にするカオスエンジニアリングツールを組み合わせることにより、さまざまな障害への対応をNW-AIが自律的に学習し続けるフレームワークを構築しました。このフレームワークでは、カオスエンジニアリングツールをデジタルツイン環境上で動作させることで、さまざまな種類の障害を発生させて、対応方法をNW-AIに学習させます。このプロセスを長期間にわたって自動実行させて膨大な量の障害を発生させることで、通常の運用範囲では起こり得ない障害についてもデータを収集することが可能となります。このように、NW-AIを自己進化させて、対応できるネットワーク障害を増やすことで想定外となる障害を極小化することが可能となります。
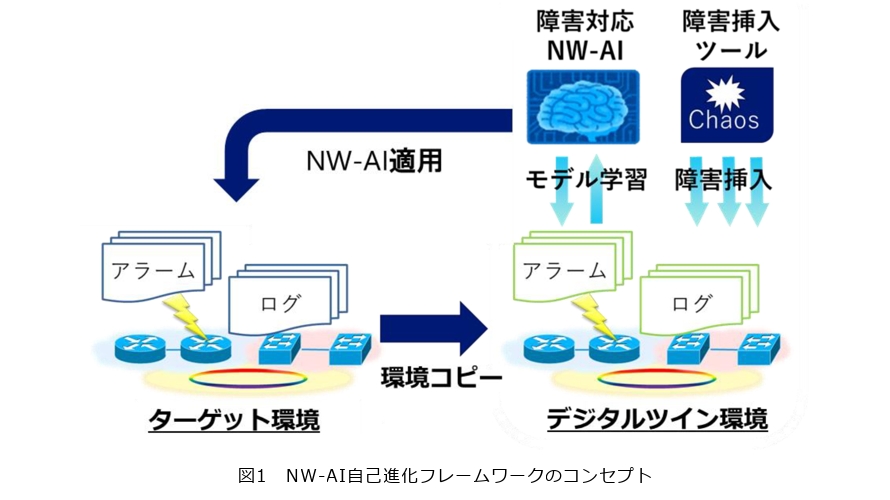
NW-AI自己進化フレームワークのコンセプト
NW-AI自己進化フレームワークのコンセプトを図1に示します。このフレームワークは、現実のネットワークを模倣したデジタルツイン環境をつくり出し、その環境上で人為的に障害状況を発生させることで、NW-AIの学習に必要な障害データを収集します。この障害状況の発生には、カオスエンジニアリングツールを使用します。
カオスエンジニアリングは、システムの弱点を発見し、それを修正することでシステムの耐久性を向上させるための実験的なアプローチです。これは、意図的にシステムに障害を引き起こし、その結果を観察することで行われます。このアプローチの目的は、システムが予期しない問題や障害にどのように対応するかを理解し、それによってシステムの弱点を特定し、改善することです。カオスエンジニアリングツールは、このプロセスを自動化し、管理するためのソフトウェアです。
カオスエンジニアリングツールを使用することで、現実のネットワーク環境では発生頻度の低い障害事例や、まだ発生したことのない障害事例についても、デジタルツイン環境で発生させてデータを収集することが可能となります。NW-AIはこれらのデータを学習することで、障害への対応方法を学習します。
このようにして大量のデータを学習したNW-AIを現実のネットワーク環境で動作させることで、ネットワーク障害からの自動復旧を実現します。
NW-AI自己進化フレームワークを用いた自動復旧AIの構築
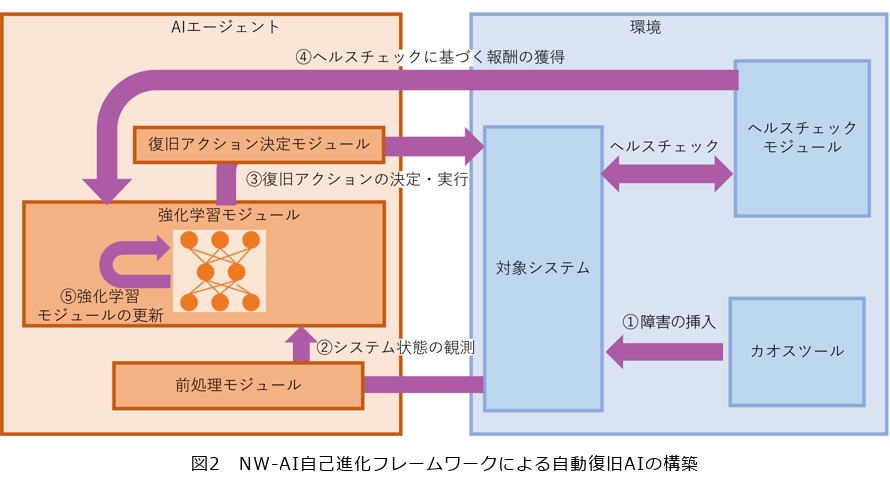
ここではNW-AI自己進化フレームワークで自動復旧AIを構築する場合の処理をステップごとに説明します(1)〜(3)。本フレームワークを用いて自動復旧AIを構築する場合のアーキテクチャを図2に示します。
本フレームワークはAIエージェントと環境から構成され、その動作はすべてスクリプトで自動化できます。AIエージェントと環境は相互作用し、復旧方策は以下のステップに従って自律的に構築されます。
① 障害の挿入
このステップでは、カオスエンジニアリングツールを用いて、対象システムにさまざまな障害を挿入します。障害の挿入は、システムの弱点を明らかにし、その対策を練るための重要なプロセスです。本フレームワークでは、頻繁に発生する障害だけでなく、発生頻度は低いが発生した場合には重大な影響を及ぼす可能性のある障害も挿入します。これにより、システムがさまざまな障害状況に対応できるようになります。
② システム状態の観測
このステップでは、AIエージェントが対象システムの状態を観測し、その情報を収集します。具体的には、一定の時間枠内にシステムから生成される各種メトリクスやログなどのデータをエージェントが収集します。これらのデータはシステムのパフォーマンスや状態を示す重要な指標であり、エージェントがシステムの現状を理解し、適切な行動を決定するための基盤となります。
③ 復旧アクションの決定・実行
このステップでは、観測データと過去の学習結果を基に強化学習モジュールが最適な復旧アクションを決定し、実行します。復旧アクションは、システムの異常状態を正常に戻すための具体的な行動で、その内容は観測データや現在のシステム状態に基づいて決定されます。例えば、特定の装置の障害が観測された場合、復旧アクションとしてその装置の再起動が選択されます。一方、ネットワーク経路に問題が検出された場合には、経路の再設定が行われます。
④ ヘルスチェックに基づく報酬の獲得と新たなシステム状態の観測
このステップでは、ヘルスチェックモジュールがシステムの状態を監視し、その結果に基づいてAIエージェントに報酬が与えられます。報酬の設定は、システムの状態が正常に近いほど高くなるように調整され、これによりエージェントはシステムの正常化をめざす行動を学習します。ヘルスチェックモジュールによる監視と報酬の設定は、エージェントがシステムの状態を適切に理解し、最適な行動を選択するための重要なフィードバックメカニズムとなります。
⑤ 強化学習モジュールの更新
このステップでは、エージェントが観測したシステム状態、選択した復旧アクション、得られた報酬、そして新たに観測したシステム状態の組合せを利用して、強化学習モジュールの更新を行います。エージェントはこれらの情報を記憶し、それらを学習データとして使用します。具体的には、エージェントは選択したアクションがシステム状態をどのように変化させ、それがどの程度の報酬につながったのかを学習します。これにより、エージェントは同様のシステム状態が発生した際に、より良い結果を得るためのアクションを選択する能力を向上させます。この強化学習モジュールの更新は、エージェントがシステムの状態とその変化を理解し、最適な行動を選択するための重要なプロセスです。これにより、エージェントは継続的に学習と進化を行い、システムの効率と安定性を向上させることが可能となります。
今後の展開
本稿では、障害に強いロバストネットワーク実現のためのNW-AI自己進化フレームワークと本フレームワークを活用した自動復旧AI構築について紹介しました。今後の展開としては、NW-AI自己進化フレームワークを用いて自動復旧を含めた各種オペレーションを自動実行するNW-AIを学習させ、障害が発生した際の迅速な自動対処を可能とすることで、障害に強いロバストネットワークの実現をめざしていきます。
■参考文献
(1) H. Ikeuchi, J. Ge, Y. Matsuo, and K. Watanabe:“A Framework for Automatic Failure Recovery in ICT Systems by Deep Reinforcement Learning,”IEEE ICDCS, pp. 1310-1315, Nov.2020.
(2) H. Ikeuchi, Y. Takahashi, K. Matsuda, and T. Toyono:“Recovery Process Visualization based on Automaton Construction,”IFIP/IEEE IM, pp. 10-18, May 2021.
(3) 池内・葛・松尾・渡辺:“障害データ生成に基づく要因特定手法の一検討,”信学会総合大会, B-7-32, 2020.

(左から)高橋 洋介/池内 光希/渡邉 暁






障害に強いロバストネットワーク実現のためのNTT研究所の取り組みについて、お伝えできれば幸いです。