2025年9月号
特集1
AIコンステレーション®を支える先端AIアルゴリズム研究
- 人工知能
- 先端AIアルゴリズム
- 非メディアデータ
本稿では、AIコンステレーション®の基盤技術としての活用を志向する先端AI(人工知能)アルゴリズムの研究事例を紹介します。具体的には、学習結果の再利用を可能にするNTT発「学習転移」技術、偏ったデータの環境変化に低ラベリングコストで適応するための転移学習技術、数値予測モデル向けのテスト時適応技術、多種多様な大規模高次元データ分析のためのスパースモデリング技術について解説します。
千々和 大輝(ちぢわ だいき)/熊谷 充敏(くまがい あつとし)
足立 一樹(あだち かずき)/井田 安俊(いだ やすとし)
NTTコンピュータ&データサイエンス研究所
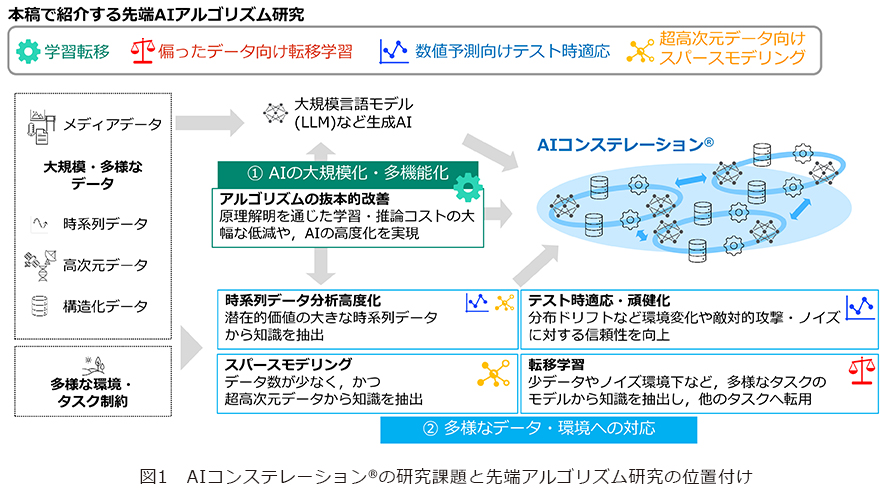
AIコンステレーション®実現に向けた研究課題
AIコンステレーション®では、さまざまな用途に応じたAI(人工知能)モデルを多数用意し連携させることで、実世界の多様で複雑な問題に解を見出します。複雑な問題の解決には、①モデルサイズやモデル数が大規模化・多機能化することが想定されるため、AIモデルの学習をはじめとした開発・運用コストの大幅な低減が求められます。同時に、実世界の多様な問題に対応するためには、②さまざまなタスク・環境にも柔軟に適応し、言語・画像といったメディアデータだけではなく、時系列データなどの高次元・非メディアデータにも対応できる汎用性が必要です。本稿では、これらの研究課題の解決に向けた先端AIアルゴリズム研究を紹介します(図1)。
学習結果の再利用を可能にするNTT発「学習転移」技術
近年の生成AIは、「基盤モデル」と呼ばれる汎用モデルと、それを目的に応じて追加学習して得られた「チューニング済みモデル」とが主な構成要素となっています。基盤モデルは、インターネット上の膨大なデータを大量のパラメータで事前学習することで幅広い知識を獲得し、一般的なタスクであれば高い精度でこなせるようになりました。一方で、一般的な方法で解けないタスクについては、学習データにそのタスクのデータが含まれていないため、基盤モデルをそのまま使用しても対応できない場合があります。また、統計的にもっともらしい結果を出力するため、ユーザの期待する出力が常に得られるとは限りません。そこで、基盤モデルに目的ごとのデータを追加学習させることで、タスクの解き方やユーザの好みを学習したチューニング済みモデルを作成・活用することが一般的となりました。これにより、チューニング元の基盤モデルに備わっていた幅広い知識を活用しながら、個別のタスクへの対応やユーザの要望にこたえることが可能となり、生成AIの活用拡大につながっています。
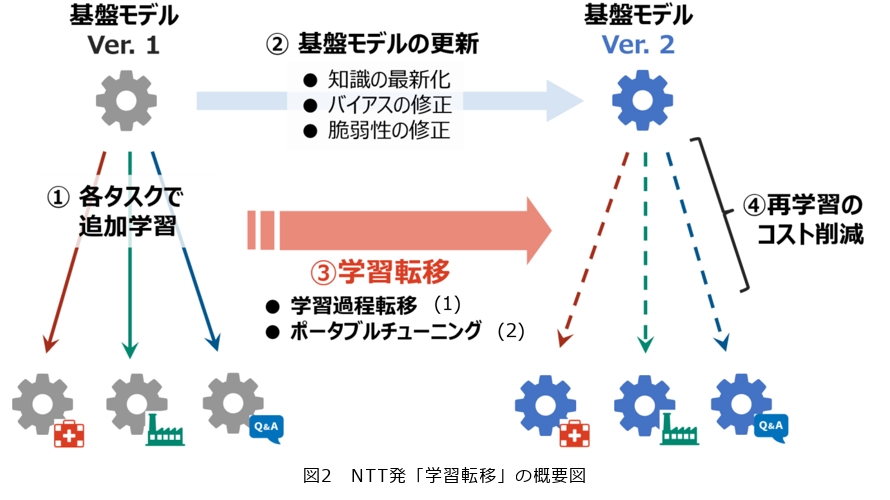
AIシステムにおける基盤モデルとチューニング済みモデルの関係は、コンピュータシステムにおけるOSとアプリケーションのような関係であるととらえることができます。コンピュータシステムの運用においては、定期的にOSのアップデートを行い、そのたびにアプリケーション側も追随させることが必要です。同様にAIシステムの運用においても、知識の最新化や脆弱性修正のため、OSに相当する基盤モデルを定期的にアップデートしていく必要性が生じます。ところが、従来技術の範疇で基盤モデルのアップデートにチューニング済みモデルを追随させるためには、アップデートされた基盤モデルに対して再び追加学習を行い、チューニング済みモデルを毎回つくり直すしかありませんでした。追加学習には推論時よりも多くの計算リソースが必要となるため、計算コストの増加が避けられないのが課題です。
このような基盤モデルのアップデートに伴う計算コストの課題を解決するため、NTTは2024年に新たなアプローチとして「学習転移*1(図2)」を提案しました(1)。学習転移の基本的な考え方は、ある基盤モデルに対する追加学習の結果を、他の基盤モデルに対しても低コストで再利用可能にする、というものです。本技術は、学習転移が実現可能であることを示唆する世界初の研究成果として、深層学習モデルのある初期パラメータに対する学習過程を、異なる初期パラメータに対する学習過程に変換できることを示しました。
一方で、本技術でも①パラメータ空間内で変換を行うためモデル構造を変更できない、②学習過程の変換により性能損失を生じるため依然として追加学習は必要、という課題が残っていました。そこで、従来の学習方法そのものを見直し、さまざまな基盤モデルに学習転移させることを前提として設計された新たな学習方法「ポータブルチューニング」を確立しました(2)。従来の学習方法では、基盤モデルのパラメータを直接最適化することで、与えられたタスク・ドメインに特化した学習が行われます。これに対してポータブルチューニング技術では、基盤モデルの出力をタスクごとに補正する「報酬モデル」を導入し、それを基盤モデルから独立したモデルとして学習を行います。この独立性により、新たな基盤モデルの推論時にも報酬モデルを再利用でき、再学習や追加学習を行うことなく特化学習と同程度の精度を達成することができました。また理論的にも、基盤モデル間の確率分布としての差が小さいほど、追加学習を行うことなく高い精度の学習転移を実現できることが保証されています。本技術を活用することで、基盤モデル更新に伴う再学習コストを削減するだけでなく、再学習させた場合に期待される効果を事前に検証するなど、今後の幅広い応用が期待されます。
*1 学習転移:過去の学習過程をAIモデル間で再利用する新たな仕組みとして、NTTが考案した学習手法。
偏ったデータ・環境変化に対し低ラベリングコストで適応可能な転移学習技術
現在のAIはさまざまなタスクで高い性能を発揮していますが、その学習には大量の「ラベルありデータ」が必要となります。しかし、多くの場合、大量のラベルありデータの収集は困難です。例えば、サイバーセキュリティや医療、製造分野では、データのラベル付けに高度な専門知識や労力が要求されるため、大量のラベルありデータを用意することは一般に困難です。このような状況下でも高性能なAIモデルを学習するための技術として、「転移学習*2」が注目を集めています。転移学習とは、解きたいタスクの限られたデータに加え、関連するタスクのデータから有用な知識を転移させることで、高性能なAIモデルを学習可能とする技術です。NTTで取り組みを進めている事例として、サイバーセキュリティ、医療診断、異常検知、不正検知などに代表されるミッションクリティカルなタスクでの活用を志向した転移学習技術を紹介します。
このようなタスクにおけるデータの特徴として、「攻撃」「異常」「疾患」「不正」といった重要なデータ(正例)の数が、それ以外のデータ(負例)に比べて極端に少ないことがあげられます。このようなデータは「不均衡データ」と呼ばれ、これに対しては、通常のAI・機械学習で用いられる正解率などの指標では正しく性能評価ができないことが知られており、「AUC(Area Under the ROC Curve)」と呼ばれる指標が標準的に用いられます。正例・負例のラベルが付いたデータを用いて、AUCの値が高くなるよう明示的に学習を行うことで、不均衡データであっても高性能なAIモデルの構築が可能となります。この学習法は、「AUC最大化法」と呼ばれ、不均衡データに対する代表的な学習法として知られています。
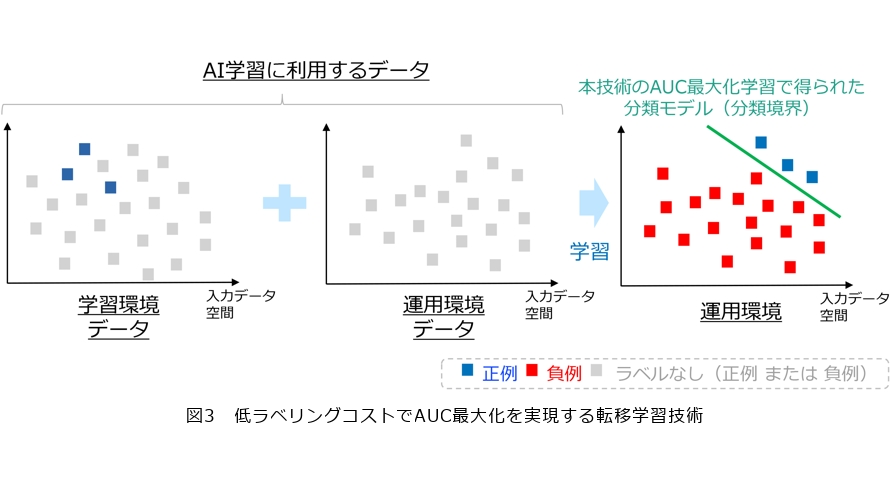
一方で、学習においてどれだけ良いAIモデルを構築したとしても、学習時と運用時でデータの分布(傾向)が変わってしまうことは避けられず、分布シフトの問題が生じます。具体的には、サイバー攻撃手法の進化や新しい異常・不正パターンの出現、あるいはデータ収集場所が変化することなどでもデータ分布は変化します。既存のAUC最大化法では、学習・運用時でデータ分布が同一であることを仮定するため、分布シフトが起こる状況ではAUC最大化法で学習したAIの性能が低下してしまう問題がありました。
この問題の解決をめざし、NTTは不均衡データ向けの新たな転移学習技術を考案しました(3)。具体的には、正例シフトおよび共変量シフトと呼ばれる特定の分布シフトに対して、学習環境(関連するタスク)で得られる正例・ラベルなしデータと運用環境(解きたいタスク)で得られるラベルなしデータのみを用いて、運用環境におけるAUC最大化を理論的に実現可能なアルゴリズムを導出しました(図3)。本技術のポイントは、分布シフト形に仮定をおくことで、本来は運用環境の正例・負例から定義されるAUCの値が、正例・ラベルなしデータのみから計算可能であることを理論的に示した点です。本技術により、不完全な教師データ(正例・ラベルなしデータ)しか得られない状況であっても、運用環境の完全な教師データ(正例・負例)を用いてAUC最大化を実行したかのような精度の良い学習が可能となります。今後は本研究を発展させ、分布シフトや不完全データといった実世界で生じるさまざまな制約下でも、安定・安全に利用可能なAIアルゴリズムを創出していきます。
*2 転移学習:あるタスクで得られたデータを活用することで、限られたデータしか得られない別のタスクでのAIの性能を向上させる技術。
数値予測モデル(回帰モデル)のテスト時適応技術
入力データから数値(連続値)を予測する回帰モデルは、製造業や医療、金融分野において取得されるセンサデータなどの時系列データや画像データに対する予測タスクを例として、さまざまな応用がある重要なモデルです。通常の回帰モデルは学習環境と運用環境が同一であること、すなわちデータ分布が変化しないことを仮定しますが、実際の運用環境のデータ分布が学習環境のデータ分布と異なってしまう、前述した分布シフトの問題が生じます。例えば画像データでは、天候や時間の違いにより明るさや周囲の物体が変化してしまうこと、センサデータでは、測定環境が変わってしまうことや測定機器自体が劣化してしまうことなどに起因し、時間の経過とともに意図せず学習環境と異なってしまうことがあります。分布シフトが発生した状態で回帰モデルを適用しても、異なる傾向を持つデータが入力されてしまうため、精度が低下してしまうことが課題となります。運用環境でモデルの精度を維持するためには、学習段階で運用環境のデータを入手して学習に用いる方法や、運用環境のデータにアノテーションを行い、モデルを追加学習させる方法などがあります。しかし、運用環境のデータを事前に収集することは高いコストを要したり、原理的に収集できなかったりする問題や、運用中のアノテーションコストが継続的に必要となるという問題があります。
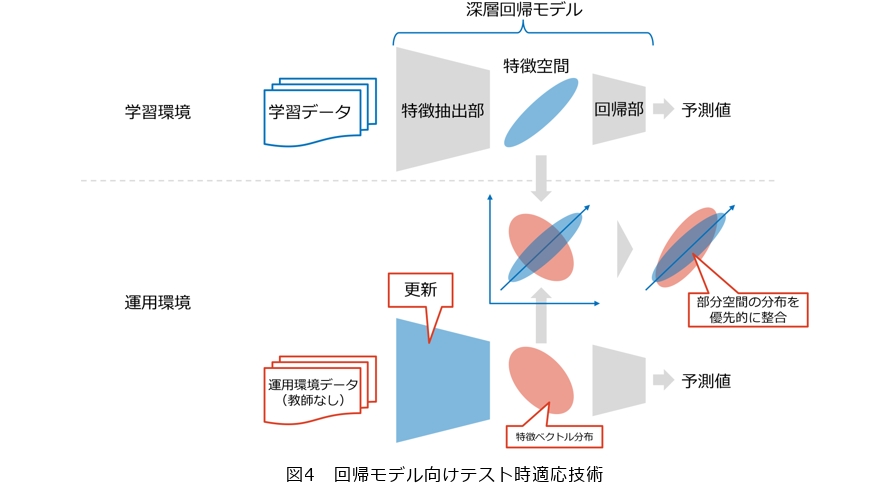
このような問題に対し、学習後に運用環境のラベルなしデータのみを用いて自律的にAIモデルを適応させる「テスト時適応*3」と呼ばれる技術の研究が行われていますが、従来の研究は与えられたデータをあらかじめ定義された複数のクラスのいずれかに割り当てるという、分類モデルに対する取り組みでした。そのため、予測時に入力データが属しているクラスを示す予測確率(例:猫80%、犬10%、鳥5%、…)を出力する分類モデルに特有の構造を前提としていました。一方で、実用上重要な回帰モデルにおいては、クラスや予測確率といった概念がなく実数値を出力するため、従来のテスト時適応手法を使うことができません。
そこでNTTでは、まず回帰モデルの特性を分析し、分類モデルとは異なる特性として「深層回帰モデルの中間層の特徴ベクトルは、高次元空間のごく一部の部分空間に集中している」ことを発見しました。これを基に、未知の運用環境の特徴分布を、学習環境の特徴分布に整合させる手法を提案しました(4)(図4)。また、特徴ベクトルが一部の部分空間に集中していることから、特徴空間のほとんどの次元はモデルの出力へ寄与が小さいといえるため、特徴ベクトルが集中している部分空間の分布を優先的に整合させることにより、回帰モデルにおける適応性能が大きく向上しました。
本技術は、モデルの出力形式に依存しないため、製造・医療・金融をはじめとした多様な事業分野で活用されているデータ分析AIに組み込むことで、環境変化に対する精度低下を防ぐことができ、MLOpsの大幅なコスト削減につながることが期待されます。また、この知見は、画像データや時系列データにおける天候変化・センサ劣化など環境変化に対して、回帰モデルに限らずマルチモーダル基盤モデルなどのさまざまなモデルに応用できると考えられ、AIの適用領域拡大に貢献します。
*3 テスト時適応:学習済みのAIモデルを適用先のラベルなしデータのみを用いて適切にチューニングする技術。
高速スパースモデリングによる多種多様な大規模高次元データの分析
近年、センシング技術の進展により、ヒトやモノから多種多様なデータを取得できるようになり、ビジネス展開や社会課題の解決に向け、そのデータ分析に注目が集まっています。これらのデータには、データ数に対して次元数(本記事では特徴量数に相当)が大きい、いわゆる高次元データと呼ばれるものが増えています。しかし、現代のAI技術によるデータ分析では、膨大なデータ数によって性能を引き出すものが多いため、相対的にデータ数の少ない高次元データの活用は難しいと考えます。
一方でこうした高次元データの分析に強い技術が「スパースモデリング*4」と呼ばれる技術です。スパースモデリングとは「得られた情報の中でも必要なものはごく一部で、そのほかの大部分は不要である」というスパース性を仮定してデータを分析する技術です。このスパース性を用いて「必要な次元はごく一部である」と仮定することで、高次元データを分析可能にします。
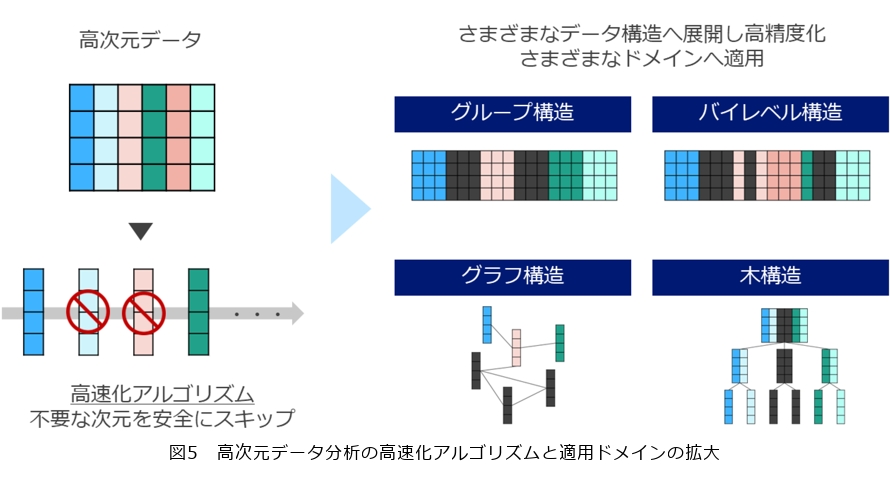
しかし、スパースモデリングにおいてもデータが高次元になるほど処理時間も長くなり、現実的な時間内でデータを分析・活用することが難しくなります。NTTではこの課題に対応するため、スパースモデリングを大幅に高速化するアルゴリズムを開発してきました。「必要な次元はごく一部である」というスパース性を活かし、不要な計算を安全にスキップする独自のアルゴリズムを導入することで、精度を損なうことなく処理時間を大幅に短縮しています(5)(図5)。
この高速スパースモデリング技術の一部は、すでにNTTの製品にも導入されています。例えばFastSGLという技術は、特徴選択という分析を精度劣化なしで最大35倍高速化しました(6)。この技術は、NTTドコモビジネスの時系列データに対するノーコード分析ツールNode-AIに搭載され、意思決定までのリードタイムを短縮し、データ分析のPDCAサイクルを高速化しています(7)。
また、高次元データの中にはさまざまな構造を持ったデータもあります。例えば地域別交通量データではグループ構造、通信網の通信データではネットワーク構造、ECサイトの商品データでは商品分類の階層構造などが挙げられます。データ数が相対的に少ない高次元データでは、こうした構造情報も同時に活用することで精度向上を期待できます。NTTではこれらの構造付き高次元データへ高速スパースモデリング技術を適用可能にすることで、高精度かつ高速な高次元データ分析技術の開発も進めています。これまでグループ構造(8)、ネットワーク構造(9)、階層構造といった多種多様な構造を持つ高次元データの分析高速化に成功し、NTT技術の適用範囲を拡大させています(図5)。
*4 スパースモデリング:「得られた情報の中でも必要なものはごく一部で、その他の大部分は不要である」というスパース性を仮定してデータを分析する技術。
今後の展開
本稿では、AIコンステレーション®への将来的な展開を見据えた先端AIアルゴリズムの研究事例を紹介しました。今後は、これらの先端AIアルゴリズムをさらに発展・深化させることで、AIモデル学習・運用の抜本的改善やセンシングデータ・時系列データといった非メディアデータでの分析高度化を実現し、実世界の複雑な問題に解を見出すAIコンステレーション®の創出に貢献していきます。
■参考文献
(1) https://group.ntt/jp/newsrelease/2024/05/07/240507b.html
(2) D. Chijiwa, T. Hasegawa, K. Nishida, K. Saito, and S. Takeuchi: “Portable Reward Tuning: Towards Reusable Fine-Tuning across Different Pretrained Models,” ICML 2025,Vancouver, Canada, July 2025.
(3) A.Kumagai, T.Iwata, H.Takahashi, T.Nishiyama, K. Adachi, and Y.Fujiwara:“Positive-unlabeled AUC Maximization under Covariate Shift,” ICML 2025, Vancouver, Canada, July 2025.
(4) https://group.ntt/jp/newsrelease/2025/03/18/250318b.html
(5) Y. Ida, S. Kanai, A. Kumagai, T. Iwata, and Y. Fujiwara: “Fast Iterative Hard Thresholding Methods with Pruning Gradient Computations,” NeurIPS 2024, pp.52836-52857, Vancouver, Canada, Dec. 2024.
(6) Y. Ida, Y. Fujiwara, and H. Kashima: “Fast Sparse Group Lasso,” NeurIPS 2019, pp.1702-1710, Vancouver, Canada, Dec. 2019.
(7) https://nodeai.io/
(8) Y. Ida, S. Kanai, and A. Kumagai: “Fast Block Coordinate Descent for Non-Convex Group Regularizations,” Proc. of AISTATS 2023, pp.2481-2493, Valencia, Spain, April 2023.
(9) Y. Ida, Y. Fujiwara, and H. Kashima: “Fast Block Coordinate Descent for Sparse Group Lasso,” The Japanese Society for Artificial Intelligence, Vol. 36, No. 1, pp. A-JB1_1-11, 2021.

(上段左から)千々和 大輝/熊谷 充敏
(下段左から)足立 一樹/井田 安俊






実世界の多様で複雑な問題に解を見出すAIコンステレーション®の実現に向け、今後も先進性と実用性を両立するAIアルゴリズムの研究を推進していきます。