2022年3月号
特集
IOWN Global Forumにおけるストレージサービスの検討
- データハブ
- データセントリック
- ストレージ
IOWN Data Hubは、IOWN(Innovative Optical and Wireless Network)時代に必要となる、データベースやストレージなどの機能を統合した新しいデータサービスを提供するものです。IOWNインフラの特長を活用しながら既存システムとの互換性を維持することで、IOWN時代の複数のアプリケーションから共通して利用されること想定して検討が進められています。本稿では、IOWN Global ForumにおけるIOWN Data Hubの議論の状況や到達点を紹介します。
井上 知洋(いのうえ ともひろ)
NTT社会情報研究所
IOWN Data Hub
IOWN Global Forum(IOWN GF)では、IOWN(Innovative Optical and Wireless Network)が創出する新しい通信・計算基盤の先進性を活かした共通的なサービスレイヤの仕組みについて複数の参加企業が協力して議論を行っています。その中でもIOWN Data Hub(IDH)は、IOWN時代のアプリケーションのためのデータハブサービス(データベース、ストレージおよびデータマネジメント等を統合したサービス)として、複数の当事者の間で高速かつ信頼できるデータ処理、利用、交換を可能にするデータ管理&共有基盤をめざすものです。
IDHはIOWN DCI(Data Centric Infrastructure)アーキテクチャ(1)の上のアプリケーション機能ノードとして実現され、IOWN Open APN(All Photonics Network)(2)やDCIの特長を活用しながら既存のアプリケーションとの互換性を維持することで、他のアプリケーション機能ノードから共通して利用されることを想定して検討が進められています。
IOWN GFでは、複数のサービスプロバイダがIDHサービスを開発・展開できるような世界をめざして、そのための共通的な基盤を定義しています。2022年1月には、NTT、Oracle、NEC等と「Data Hub Functional Architecture」文書(IDH文書)(3)を公開しました。
■IDHが規定するもの
IOWN GFで議論されているさまざまなユースケースにおいては、データハブサービスに期待される複数の要求パターンがあります。IOWN GFではこれらの要求を類型化し、いくつかのService TypeおよびService Classとして整理しました。IDH文書では、各Service ClassについてIOWNのインフラを用いたリファレンス実装モデル(Reference Implementation Model)を示しています。
IDH Service TypeとService Class
■必要なデータハブサービス
IOWN GFではいくつかのユースケースについて、その具体化に向けたシステム構成案やデータフローの検討を行っています(4)。この検討は、既存システムにおけるレイヤ構成にとらわれず、IOWNのインフラを用いたフルスタックの最適化をめざすもので、通信レイヤからサービスレイヤまでを幅広く扱うIOWN GFならではの非常にユニークな取り組みとなっています。それでも、分析の結果として得られたデータフローは、現在のインターネット・アプリケーションが要求するデータフローと概念的にはかなり近いものです。IOWNの普及当初のアプリケーションが用いるデータフローは、互換性の観点から、現在のアプリケーションと大きくは変わらないと想定されます。これらの議論を踏まえて規定されたService TypeとService Classについて紹介します。
■Service Type
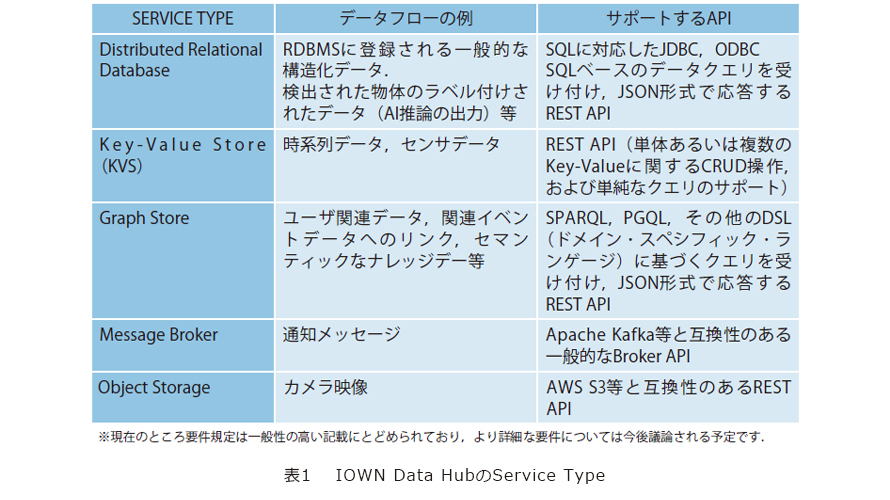
Service Typeは、IDHサービスに実装される機能および動作の単位として定義されます。具体的にはサポートするAPIやクエリ、データタイプなどの要件が定められており、外部アプリケーションはService Typeを指定することでIDHサービスをデータベースやオブジェクトストレージのように扱うことが可能です。現在定義されている5種類のService Typeは以下のとおりです(表1)。
(1) Distributed Relational Database(DRD)
DRDは構造化されたデータを格納するためのService Typeで、一般的なデータベースでのOLTPや、データウェアハウスでのOLAPのようなデータ分析のユースケースを想定しています。このService Typeを利用することで、データハブの外部で余計なデータ変換処理を行うことなく、さまざまなアプリケーションがデータを保存・利用できるようになります。ある種の構造的なクエリによって識別可能な個々のデータは、処理速度が許す限り、DRDで扱うことが望ましいでしょう。
(2) Key-Value Store(KVS)
KVSは、1レコードのサイズがそれほど大きくないが膨大な数のデータを保存する際に利用されるService Typeです。例えば、時系列データやセンサデータなどがこれに該当します。
(3) Graph Store
このService Typeは、グラフとしてモデル化されたデータを保存します。保存されたデータは、オントロジーと呼ばれるあらかじめ定義されたスキーマに従っている場合があります。オントロジーは、データがどのように構造化されているかを記述し、アプリケーション開発者がセマンティッククエリを形成することを可能にします。セマンティッククエリは、連想や文脈の範囲に基づいて情報を検索することができます。
(4) Message Broker
このService Typeは、既存のデータストレージに単純にデータを追加できない以下のような状況での利用を想定しています。
・メッセージ数が非常に大きいため、他のService Typeでは収容できず、何らかのキューに格納する必要がある。
・データの提供者と利用者の数が膨大で、動的に変化する。
・大きさや種類、形式が複数混在したデータを扱い、フォーマット変換や集計など複雑なパイプラインが必要となる。
・メッセージの中継だけが必要であり、データの永続性を必要としない。
(5) Object Storage
動画、画像、ログなどの半構造化データや非構造化データなど、比較的大きなオブジェクトデータを低コストで保存するService Typeです。ビッグデータの長期間保存や、将来のデータ活用に備えてAI(人工知能)やデータレイクなどのデータ間の分析アプリケーションを提供することが想定されます。
■Service Class
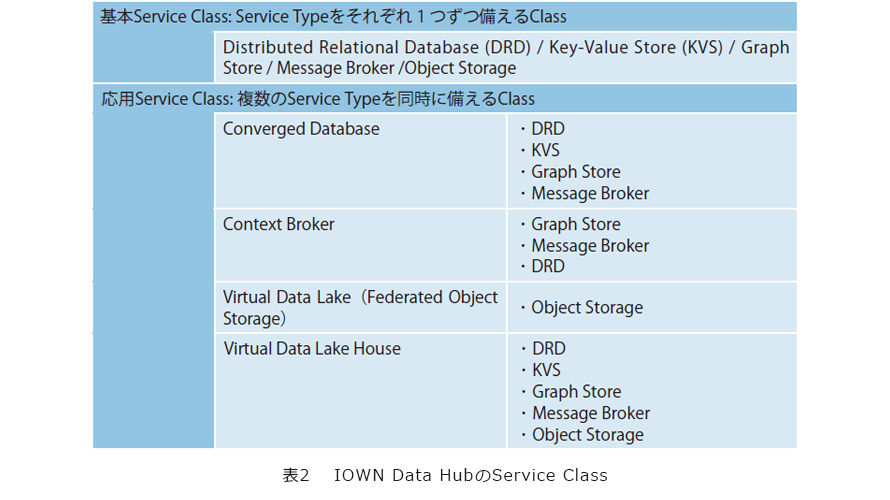
IOWNのユースケースを実現するためには、1つのService Typeを実装したIDHサービスでは不十分で、複数のService Typeが同時に必要となる場合もあります。IDHでは、1つまたは複数のService Typeを備えるサービスの実装として、表2に示されるService Classを定義しています。
基本Service Classは、各Service Typeを1つだけ継承します。応用Service Classは、より複雑なユースケースがデータハブに対して一括で求める機能をパッケージとして提供するもので、複数のService Typeを継承・統合しています。IDH文書では以下が定義されています。
■Converged Database
異なるタイプのデータを同時に処理する場合を想定したService Classです。例えば、建物内での人の行動を分析して適切なサポートを提供するというシナリオを考えた場合、人、人と人、人とモノのインタラクションをまとめて管理・処理する必要があり、これを表現するデータ構造には大きな柔軟性が求められます。しかし、データ構造ごとに異なるIDHサービスを使用し、アプリケーションレベルでデータ構造の変換を行う場合、IOWNで求められるリアルタイム性は実現できません。Converged Databaseは、このようなニーズにこたえるために、さまざまなデータを高速に同時処理する基盤を提供します。
■Context Broker
このService Classは、アプリケーションがデータを要求する際に、コンテキストを指定した柔軟なデータの指定が可能な高機能なブローカーとして機能します。コンテキストは、モノ(特定の建物など)、モノの種類、地理的な範囲、時間的な範囲、またはこれらの組合せで表現され、これによって特定の条件の情報が指定可能になります。
■Virtual Data Lake(Federated Object Storage)
このService Classは、現在広がっているデータレイクの概念を拡張し、IOWNインフラだけでなく、クラウドやオンプレミスなど地理的に分散したデータソースを仮想的に統合し、統一されたデータレイクとして提供するものです。IOWNの多様なユースケースの実現を考えた場合、すべてのデータがIOWNインフラ内で管理されるとは限らず、複数のクラウドやエッジ、オンプレミス環境にあるデータを横断して分析・処理するケースも想定されます。このためVirtual Data Lakeでは、複数の地理的に分散したストレージを束ねて1つのオブジェクトストレージとして見せる仕組みを提供します。
■Virtual Data Lake House
IOWNでは、複数の企業や組織が持つデータをオープンかつセキュアに共有し社会課題を解決する未来を想定しています。例えば、再生可能エネルギーが供給の大半を占める社会においては、電力供給量のデータに加えて、各企業や家庭における電力需要をリアルタイムに共有することで系全体の安定的な制御が可能なると考えられます。このような目的のため、Virtual Data Lake Houseは、異なる所有者に属するさまざまなデータソースへの安全で透過的なアクセスを提供します。
IDHの特長
前述のとおり、IDHは将来のアプリケーションがデータベースやストレージサービスに要求する多くの機能をサポートします。一方で、IDHはIOWNの特長を活かして、今までのデータベース等ではインフラの制約により機能や性能的に不十分であったことを実現します。ここでは、現状の制約とIDHにおいてどのように解決していく見込みかを説明します。
■現状の制約
例えば現在のクラウドのモデルで実装されたObject Storageサービスを利用して10GBクラスのデータをアップロードまたはダウンロードすると、クライアントから実際にデータを保管するストレージまでの間にある多段のデータコピーがボトルネックとなり、安定したパフォーマンスは保証されません。また現在の技術では、DRDにおいて複数のサーバにまたがってペタバイトクラスのデータを結合する必要のあるような複雑なクエリでは、データベースサーバ間のネットワーク接続がボトルネックになり、非常に時間がかかります。同様に、数エクサバイトのデータをストレージから読み込むフルスキャンタイプのクエリでは、ストレージからのデータ転送がボトルネックになります。IDH文書では、その他のService Classについても、現状のクラウドベースの実装における制約を指摘しています。
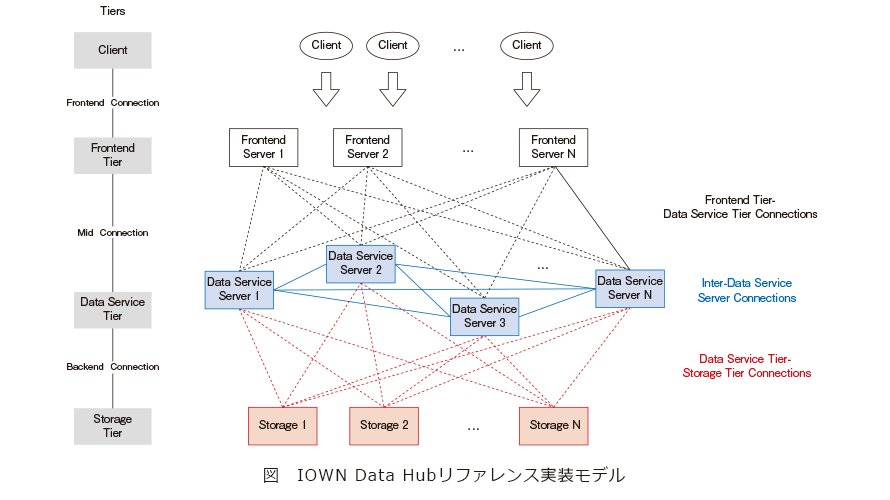
■リファレンス実装モデルの構成と改善点
IDHのリファレンス実装モデルを図に示します。Service Classごとに詳細は異なりますが、この構成はすべてのClassに共通的な内部構成となります。この構成は、IDHサービスへのデータ要求を行う「Client」、ロードバランシング、クエリルーティング、プロトコル変換等を提供する「Frontend Tier」、データアクセス要求に応じてローカルキャッシュまたは接続されたストレージ層からのデータを提供する「Data Service Tier」、およびデータの保存する「Storage Tier」の4つの層から成り、各層は複数のコンポーネント(サーバ等)で構成されます。IDHでは、IOWNのインフラ技術を使うことによって層間・コンポーネント間の接続や各コンポーネントの動作を以下のように高速化します。
(1) Client、Frontend Tier、Data Service Tier間の通信の最適化
ClientはFrontend Tierを介してData Service Tierからデータをやり取りします。リアルタイムに近い処理を実現するためには、これらの通信のための遅延を短くし、特に大量のデータを繰り返し転送する必要がある場合には帯域を広くする必要があります。IDHでは、Open APNが提供する2つのエンドポイント間の直接的な光通信によって、低遅延・広帯域な接続を必要に応じて確保します。
(2) Data Service Tier内の通信の最適化
データ処理が頻繁に発生しData Service Tier内のサーバ間で大量のデータがやり取りされる場合、サーバ間の通信がデータサービスにおけるボトルネックになります。特に、現在使われるTCP等のブロッキングプロトコルを用いたサーバ間通信の実装では、I/O(Input/Output)の待ち時間によってサーバのCPUサイクルを浪費しがちです。IDHでは、複数のリソースを動的に組合せ可能なDCIの仕組みによって、高性能なクラスタを構築することができます。さらに、DCIにおけるプロトコル最適化(例えばRDMAを用いた高速なノンブロッキング通信)を用いることで、膨大な量のデータをほぼリアルタイムで処理・管理できるように設計されます。
(3) Data Service Tier、 Storage Tier間の通信の最適化
IOWNのユースケースでは、1回のリクエストで転送されるデータ量が合計数100TBになることも想定されますが、Data Service TierとStorage Tierの通信にネットワーク帯域が不足している場合、サービスが長時間応答しない状態になってしまいます。Open APNによるネットワークの広帯域化や、DCI (RDMA)によるデータ転送の最適化はこのボトルネック解消にも役立ちます。
(4) 各コンポーネントのスマート化
ネットワークの高速化に加えて、IDHでは、スマートNICなどを使ってデータの前処理等を積極的に各コンポーネントにオフロードしていきます。例えばStorage Tierのコンポーネントがデータのフィルタリングやアグリゲーションを行うことで、ネットワーク上のデータ転送量を100分の1以下に減らすことができます。また、データがData Service Tierのどこに配置されているかをClientやFrontend Tierに配信することで、データアクセス要求を最適なコンポーネントに直接送ることができ、コンポーネント間の余分なデータ転送を減らし遅延と帯域幅を改善することができます。
このような仕組みにより、IOWNのリファレンス実装モデルは、現在のクラウドベースの実装モデルよりもはるかに高速に動作することが期待されます。IDH文書では、各Service Classの実装モデルにおけるより具体的な工夫点が記載されています。
IDHの今後
IDH文書は、IOWNインフラにおけるIDHの技術的な位置付けをまとめ、既存のクラウド型データ処理のボトルネックを解決するためのリファレンス実装モデルを提示しました。しかし、これはIDHの特長を実現するための最小実行構成(Minimum Viable Version)と呼ぶべきものです。IOWN GFによる今後の議論によって、各Service TypeのAPIの詳細化やより良い実装モデルの議論等が進められていく予定です。また、今後のIOWNアプリケーションが必要とする高度なデータ処理フローには、より高度な機能が必要になると考えられます。例えば、スマートシティなどのユースケースでは、複数の組織が所有するデータを複数のデータ利用者が横断的に取り扱う必要が出てきます。そのために、認証・認可の仕組みの整備や、データ利用に関するポリシーの制御や監査に対応できる仕組みが必要となります。さらには、データを秘匿したまま処理を実行する秘密計算のような仕組みもデータハブの一機能として検討が必要です。IOWN GFコミュニティでは、IOWN時代に必要となるデータハブサービスのあるべき姿について引き続き議論を進めていきます。
■参考文献
(1) https://iowngf.org/technology/#Data-Centric-Infrastructure
(2) https://iowngf.org/technology/#Open-All-Photonic-Network
(3) https://iowngf.org/technology/#Data-Hub
(4) https://iowngf.org/technology/#Reference-Implementation-for-CPS-AM

井上 知洋







IOWN GFでは、IOWN時代の次世代データサービスの実現・普及に向けて、NTTグループだけでなくさまざまな企業が力を合わせて検討を進めています。多くのパートナー参画を期待します。