2023年12月号
特集1
IOWN Data Hubの実現に向けた取り組み
- ストレージ
- データベース
- 仮想データレイク
IOWN Global Forumでは、IOWN(Innovative Optical and Wireless Network)技術の社会実装に向けた取り組みが進んでいます。本稿では、新たに発行されたIOWN Data Hub Functional Architecture 2.0およびPoC(Proof of Concept) Referenceを中心に、IOWN Global Forum におけるストレージサービスの検討の進捗ならびにNTT研究所におけるIOWN Data Hub(IDH)に関連する取り組みについて紹介します。
南端 邦彦(みなみはた くにひこ)†1/井上 知洋(いのうえ ともひろ)†2
髙屋 和幸(たかや かずゆき)†3
NTT研究企画部門†1
NTT社会情報研究所†2
NTTソフトウェアイノベーションセンタ†3
IOWN Data Hubが求められる背景
現実世界とバーチャル世界を融合し、バーチャル空間でのシミュレーション結果を現実にフィードバックすることで、察知した危険に迅速に対応したり、変化を最小限に抑え心地良い環境を維持したりするなど、さまざまな恩恵を受けることができるようになります。しかし、その融合のためには、現実世界でセンシングされた膨大なオブジェクトのデータやその動作をリアルタイムにサイバー空間と同期させる必要があります。現状のネットワークではその遅延の大きさから、広範囲に膨大なデータを同期させることは難しく、広大な空間に高精細なデジタルツインを構築することは困難です。そのため、現実世界で分散したデータを超高速で流通させるための仕組みとして、IOWN(Innovative Optical and Wireless Network)のインフラであるOpen APN(All-Photonic Network)やDCI(Data-Centric Infrastructure)のうえに構築された新たなデータ流通基盤となるIOWN Data Hub(IDH)が必要となります。本稿では、IDHアーキテクチャ文書のアップデートと、IDHの実現に向けたPoC(Proof of Concept)の取り組みにフォーカスして紹介します。
IOWN Global ForumにおけるIDHの活動
2022年1月、IOWN Global ForumメンバであるNTT、Oracle、NEC等が協力し、IOWN Data Hub Functional Architecture 1.0を策定、公開しました。IDHの基本的な仕組みやコンセプトについては、本誌『IOWN Global Forumにおけるストレージサービスの検討』(1)を参照ください。その後、IOWN Global Forumで社会実装に向けた議論を重ね、2023年7月、IOWN Data Hub Functional Architecture 2.0(2)にアップデートしました。主なアップデートのポイントは、以下2点です。
① ユースケース要件の具体的提示:CPS/AICユースケース文書(3)(4)で提示する各ユースケースのデータ種別、必要な帯域幅などの要件を整理
② ギャップの本質化:より具体的な実装モデルに基づくギャップ分析
上記①で記載しているユースケースの要件を表1にピックアップしました。これら将来のユースケースは、データ処理と共有に関する多様で厳しい要件を満たす必要があります。例えば、リアルタイムの要件を満たすには、元のデータに近いそのままのデータを処理する必要があり、大量のデータフローに対応するためには、超高速かつ高品質なネットワーク上で動作するように、分散型データ管理エンジンの大幅な改良が必要となります。将来的には、複数の当事者間で高速かつ信頼できるデータ交換を行うための堅牢なデータセキュリティとデータ利用を制御するメカニズムが求められるようになるでしょう。
上記②では、今日のコンピューティング環境におけるギャップに加え、それを構成するデータセンタやデータ流通、処理モデルにおける問題点を抽出しています。

■データセンタにおける基本的な課題
ユースケースの要件を満たすIDHサービスを構築する際には、次に挙げるような現在のネットワークおよびデータセンタ技術におけるいくつかの基本的な問題があります(図1)。
(1) データセンタ間のネットワーク品質
今日のクラウドで利用されるデータセンタ間のネットワーク品質は、現状のユースケースにフォーカスされており、パケットの並べ替えや損失が起こるため、信頼性を確保するためにTCP(Transmission Control Protocol)がUDP(User Datagram Protocol)などの他のプロトコルよりも頻繁に使用されます。これらのネットワークでは、IOWN時代のユースケースが求める地理的に分散されたデータベースやストレージシステムなどのワークロードのパフォーマンスが十分に発揮できません。
(2) データセンタ内のネットワーク品質
クラウドを構成するハイパースケールデータセンタでは、リソースを接続するネットワーク品質が十分ではありません。例えば、片方向の遅延は1ミリ秒を超えることがあり、深刻なネットワーク輻輳時にはパケット損失が1%を超えることがあります。帯域幅も同様に不安定です。これは基本的にネットワーク装置が持つ容量を超える帯域予約を可能にするオーバサブスクリプションによるもので、実際にはデータセンタ内のコンピューティングリソースどうしをつなげるネットワークは、各リソースに割り当てられた総帯域幅を保証できません。
(3) ストレージ・パフォーマンス
データの永続性を確保するために、ストレージは通常、複数のサーバにデータを同期します。しかし、同期には負荷が大きくかかるため、パフォーマンスはとても不安定になります。その結果、今日のクラウドのストレージエリアネットワークを介して接続されたストレージシステムは、直接接続されたストレージデバイスよりも動作が遅くなる傾向があります。例えば、ストレージシステムの応答時間は数10ミリ秒を超えることがあり、一般的なデータベースのワークロード、さらには冗長化されたストレージシステムには適していません。
(4) データ共有のパフォーマンス
データを複数のサーバで協調して処理する場合、データの再配布など、サーバ間で一定量のデータ交換が必要となり、全体の性能に大きく影響します。このようなデータサーバを高速化するために、一部の実装ではRDMAファブリック接続でサーバ間をつなぎます。しかし、実運用環境でのRDMAの適用は、パケットの損失がなく順序入れ替えも起こらないという厳しい要件が必要なため、今日のクラウド環境では非常に限られた目的でしか使用されていません。
(5) アクセラレータの使用
GPU(Graphics Processing Unit)やFPGA(Field Programmable Gate Array)などのアクセラレータは、汎用CPU上のソフトウェアベースの処理に比べて、10倍以上のパフォーマンス、コスト効率、およびエネルギー効率を達成する可能性があります。しかし、このようなアクセラレータの使用は、各サーバ内に配備する必要があり、またデータロードを合理化するために外部のクライアントに直接アクセスできません。したがって、現在のネットワークおよびデータセンタ技術では、高速かつ低オーバヘッドで複数の汎用コンピューティングリソース間でアクセラレータリソースを共有することはできません。

■今日の実装モデルと本質的なギャップ
前述の問題を踏まえ、IDHのようなデータサービスを今日の技術で実現するためには、以下のような制約を受け入れる必要があります。
(1) 1カ所でのデータ処理の完了
データセンタ間ネットワークの品質の問題で処理効率が著しく低下する場合、地理的に分散したデータサービスの実現は困難になります。現在のサービスは、単一のデータセンタ内、または近隣のアベイラビリティゾーン内に実装されるように設計されています。実際、今日のクラウドはそのようなサービスの集合体になっているため、クラウドデータセンタの規模は巨大になり、利用可能なクラウドリージョンの数は、世界中で多くても30程度であり、非常に限られています。つまり、データの生成場所に関係なく、すべてのデータをクラウドデータセンタのいずれかに転送し、すべてのデータ処理をそこで完了する必要があるため、エネルギー消費の点では非常に効率の悪いシステムになってしまいます。
(2) スケーラブルなトランザクション分散RDBを構築するための基盤としての非同期データ・レプリケーション
一般的に、スケーラブルなトランザクションRDB(Relational Database)システムを構築するために、複製された読み取り専用のデータを各RDBサーバの近くに配置します。しかし、このような複製は、ネットワークのパフォーマンスが遅いため、非同期的に実行される傾向があります。また、低速ネットワークでのデータ複製の負荷を軽減するため、データそのものでなく、しばしばトランザクションログまたは変更ログのみを伝播します。この場合、性能は向上しますが、各サーバのログデータからテーブルデータを再構築する必要があり、その処理のためのコストや消費電力の増加は避けられません。
(3) スケーラブルなKVS、Message Brokerと分析用分散RDBを構築するためのシャード化されたデータ処理
シャードとは、関連するデータをまとめて複数のデータベースに分散させることで応答時間を短くし、スケールできるようにする技術です。KVS(Key-Value Store)などのスケーラブルなシステムを構築するために使用されます。しかし、データ再配置のための移動やサーバ間の通信はなくならず、むしろ、さまざまな角度からデータを扱う必要がある高度なデジタルトランスフォーメーション(DX)サービスでは、より増加する可能性があります。さらに、シャード化されたシステムではスケールアウト操作とスケールイン操作の間に一定量のデータ移動が必要であるため、今日のクラウドにおけるデータサービスでは、スケーラビリティの動的な変更について制限されています。
(4) キャッシュ層の利用
低速なネットワークとストレージシステムによる制約により、データはプロセスごとに管理され、非同期な分散処理が多用される傾向にあります。実際、現在のクラウドでは、このような実装を合理化するために、さまざまなキャッシュデータ管理サービスが提供されています。しかし、これによってエンド・ツー・エンドの遅延が増加し、同じデータがクラウド内で複数回余計にコピーされてしまうため、コストとエネルギー消費の点で望ましくありません。
(5) 実験段階にあるアクセラレータの利用
前述の問題解決の方向として、GPUやFPGAなどのアクセラレータを用いて、分散RDBにおけるクエリなどのデータ処理を高速化することが考えられます。実際にこのようなソフトウェアが開発され検証されていますが、実用的にはパフォーマンスとコスト効率はほとんど改善されず、しばしば悪化します。これは主に、アクセラレータの起動時にデータを事前にロードする必要があるためです。
IDHは、今日のクラウドが有する基本的、本質的な課題を解決するよう設計する必要があり、これからますます求められる広範囲かつリアルタイムなサイバー・フィジカルシステムのユースケースに適応するために、さらなる技術開発を進めていかなくてはなりません。そのためには、実際にユースケースに沿って繰り返しIDHの検証を行い、さらなるフィードバックを通じて必要な機能や設計手法をより具体化していく必要があります。
IDHに関するPoCの取り組み
IOWN Global Forumは、このIDHの実現に向けて、2022年10月にIOWN Data Hub PoC Reference(5)を策定しました。Open APNによりハイブリッド・マルチクラウド接続が超高速化されるに伴い、ハイパースケーラの一極集中からエンタープライズデータセンタやエッジクラウドの活用がより進むことが想定されます。そのため、それに合ったデータ流通のアーキテクチャ変革が求められています。IDHは、これまでハイパースケーラがセントラルクラウドで行っていた処理・機能群をディスアグリゲートし、エッジクラウドなどにそれらを再配置します。IOWN Global Forumは、このOpen APNやDCIで接続される新たなIDHアーキテクチャを多くのユースケースで検証し展開を図るため、本PoCリファレンスを公開し、IOWN Global Forumのメンバに限らず広く仲間を募っています。
■IDH PoCリファレンスについて
本PoCリファレンスは、さまざまなDXサービスの厳しい要件を満たすIDHアーキテクチャを検証するために策定されました。本リファレンスでは、ユースケースの例として、スマートファクトリー、スマートグリッド、メタバースを挙げ、5つのPoCシナリオを定義しています。
例えば、一般にメタバースサービスを構築するには、参加者に関する情報を収集し、仮想空間内でアバターとして表現し、仮想空間内でアバターが相互に対話できるようにする必要があります。そのためには、高品質なメタバースサービスにおいて、以下の要件を満たさなければなりません。
・最大数100万人の参加者のモーションデータを収集し、数10ミリ秒のサイクルでそれぞれが対応するアバターの動きに反映
・多くの仮想建物やその他の構造要素を含む仮想空間内でアバターを移動させ、相互にコミュニケーション
・アバターの視点に基づいて、数10ミリ秒以下のモーションtoフォトンレイテンシーで仮想空間の風景をレンダリング
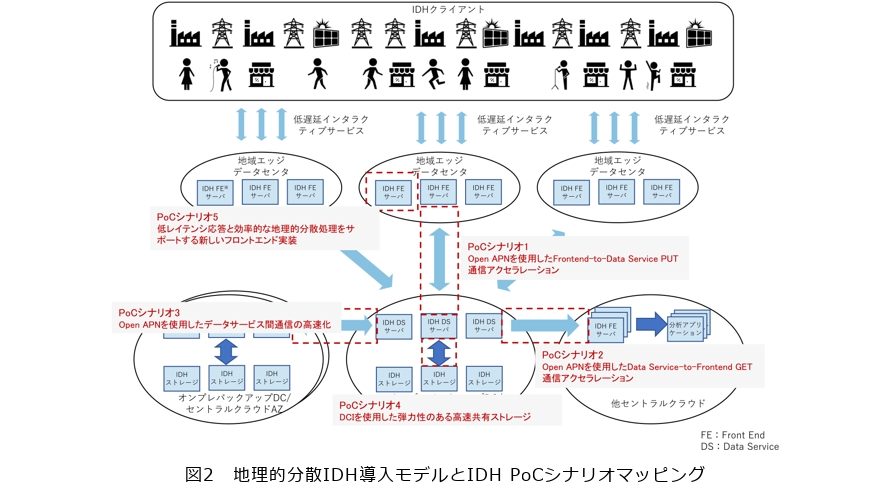
このようなユースケースに対応したIDHアーキテクチャを実証するために、前提となるIDHサービスの地理的分散展開を考慮したPoCテスト環境を定義し、PoCを行うべきポイントを示しています(図2)。
本モデルでは、IDHシステムのフロントエンドサーバのサブグループをリージョナルエッジセンタに配置し、接続されたIoT(Internet of Things)デバイス等に対して低遅延のサービスを提供します。IDHシステムの一部であるデータサービスサーバやストレージサーバを遠隔地のデータセンタやセントラルクラウドに配置し、データの永続化やデータの利用をサポートします。
このモデルをベースに、以下の5つのPoCシナリオを規定しています。
・シナリオ1:Open APNによるFrontend-to-Data Service PUT通信の高速化
・シナリオ2:Open APNによるデータサービスからフロントエンドへのGET通信の高速化
・シナリオ3:Open APNによるデータサービス間通信の高速化
・シナリオ4:DCIを使用したエラスティック高速共有可能ストレージ
・シナリオ5:低遅延応答と効率的な地域分散処理をサポートする新しいフロントエンドの実装
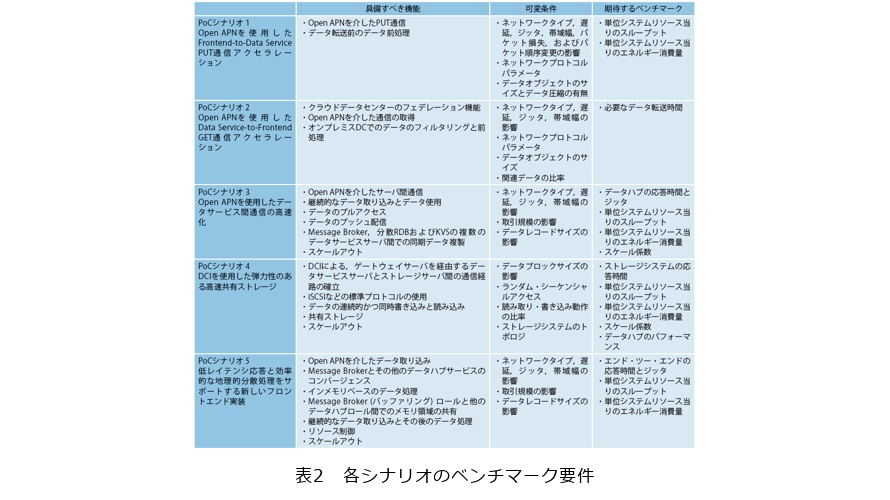
さらにそれぞれのシナリオに対して、概要、具備すべき機能、可変条件、期待するベンチマーク等が記載されており、読者がこれらの情報に基づいてIDHのPoCを進められるようになっています(表2)。
現在、IOWN Global Forumメンバ各社が、本PoCリファレンスを参考にそれぞれのシナリオに関するPoCを始めており、IDHの実現に向けた取り組みが着実に進んでいます。
NTTグループにおける取り組み
NTTソフトウェアイノベーションセンタでは、IDHの実現に寄与するため、IDHリファレンスアーキテクチャの機能セットとして定義されている仮想データレイクなどの研究開発を進めています。
デジタルツインコンピューティングで構成される仮想世界と現実世界には、さまざまなステークホルダが存在しています。冒頭で述べたようなフィードバックループをリアルタイムで回すためには、データを高速に伝送するだけでなく、立場の違うステークホルダ間でセキュアにデータ交換を行えなければなりません。そのため、流通させるデータのガバナンスを永続的に保ちながら、最新のデータがあたかも手元にあるかのように扱えることが必須になります。
NTTソフトウェアイノベーションセンタが開発中の仮想データレイクは、異なる組織・企業が管理し、地理的にも多拠点に分散している遍在データを仮想的に集約・一元化し、データ利用者がオンデマンドに必要なデータのみを効率良く取得・活用することを可能にします。そのために、データ利用者が膨大なデータの中から必要とするデータをメタデータ(データの意味情報や形式情報など)に基づいて探索・発見する機能や、データ提供者が定めたポリシーに基づいて許可されたデータのみをデータ利用者に表示・利用させてガバナンスを維持する機能などを備えます。これらにより、組織・企業の垣根を越えた多種・大量データの、速く、容易で、安全確実な相互利活用を実現します。
今後、IDHプラットフォームを実用的なものにするために、IDH PoCリファレンスなどを参考に、実証を行っていきます。
今後の展開
IDHは、Open APN、DCI上で動作するデジタルツインコンピューティングを支える“データベース is ネットワーク”のプラットフォームとして、例えば広域の自動運転といったミッションクリティカルなユースケースへの活用も今後期待されます。NTTは、多くのパートナーと一緒に、IOWN時代のユースケース要件を達成するIDHのさまざまな実装モデルを検証し、社会実装を進めていきます。
■参考文献
(1) 井上:“IOWN Global Forumにおけるストレージサービスの検討,”NTT技術ジャーナル,Vol.34,No.3,pp.23-27,2022.
(2) https://iowngf.org/wp-content/uploads/formidable/21/IOWN-GF-RD-Data_Hub_Functional_Architecture-2.0.pdf
(3) https://iowngf.org/wp-content/uploads/formidable/21/IOWN-GF-RD-CPS_Use_Case_1.0.pdf
(4) https://iowngf.org/wp-content/uploads/formidable/21/IOWN-GF-RD-AIC_Use_Case_1.0.pdf
(5) https://iowngf.org/wp-content/uploads/formidable/21/IOWN-GF-RD-IDH-PoC-Reference_1.0.pdf

(左から)南端 邦彦/井上 知洋/髙屋 和幸






次世代のデータ流通プラットフォームをめざすIDHは、多くの皆様と一緒につくり上げる必要があります。ぜひIDHにご興味をお持ちいただき、社会実装に向けた取り組みを一緒に進めていきましょう。