2024年1月号
特集1
LLM+× IOWN ~IOWNの進展、NTT版LLMの誕生、そして2つの相互作用~

本記事は、2023年11月14~17日に開催された「NTT R&D FORUM 2023 ― IOWN ACCELERATION」における、木下真吾NTT研究企画部門長の基調講演を基に構成したもので、NTT 版LLM(Large Language Model)「tsuzumi」とIOWN(Innovative Optical and Wireless Network)の実用化に向けた取り組みについて紹介します。
木下 真吾
NTT執行役員
研究企画部門長
LLMの誕生
NTTでは、NTT版LLM(Large Language Model)「tsuzumi」を開発し、2023年11月1日に報道発表しました。ここではtsuzumiの4つの特長を紹介します。
■軽量
まず1番目の特長が軽量ということです。LLMはパラメータ数の競争に入っており、非常に大規模化しています。そのため、課題はサステナビリティといわれています。例えばGPT-3のパラメータ数は17Billion(B)で、1回の学習に約1300MWhの電力が必要だといわれてます。これは原発1基1時間分の電力量に相当します。これに対してtsuzumiは次のような戦略を持っています。
めざす方向性としては、何でも知っている1つの巨大なLLMではなく、専門知識を持った小さなLLMをつくろうと考えています。そのためのアプローチとしてパラメータサイズを単純に増やすだけではなく、それに加える学習データの質と量を向上させることによって賢くさせていきます。今回tsuzumiを2種類発表しました。超軽量版tsuzumi-0.6Bは、パラメータサイズが0.6BでGPT-3の約300分の1となっています。軽量版tsuzumi-7Bは、GPT-3の25分の1のサイズとなっています。このように軽量化するメリットの1つとして、学習コストが非常に低く済みます。例えばGPT-3相当の学習を行うのに、4.7億円ぐらい1回の学習にかかるといわれています。それに対してtsuzumi-7B、0.6Bは、それぞれ1900万円、160万円と25分の1から300分の1の低コスト化を図ることができます。
もう1つのメリットとして推論のコストがあります。言語モデルを使うときのコストです。GPT-3の場合は上位機種のGPUボードが約5枚必要となり、金額換算で約1500万円かかります。これがtsuzumi-7B、0.6Bでは、約70万円、20万円となります。GPUの数では、各々下位のGPUを1基、CPUを1基で済みますので、低コスト化につながります。
■言語性能
2番目の特長が言語性能です。GPT-3.5に「日本のエネルギー政策と環境保護のバランスについて、現状と改善策を提案してください」という質問をして出てきた答えを図1に示します。図1左を見るときちんと分析されたかたちの日本語が出ていると思います。このように、tsuzumiやGPT-3、他のLLMにも同じ質問をして、どちらの性能が高いかを比較したものが、データ分析・自動化技術RakuDAのベンチマークです。例えば、tsuzumi対GPT-3.5に同じ質問をして、出てきた回答をGPT-4にインプットして、どちらが優れているかの勝率を判定し、勝敗を決めます。GPT-3.5には52.5%で勝っており、残りの4つは日本のトップクラスのLLMですが、これも71.3%、97.5%というかたちで圧倒的な勝率を誇っています。
また、質問に対し日本語で答えるだけではありません。人工光合成という研究の発表を最近行いましたが、それに対して「デバイス名、実現したこと、展示イベント、今後の予定という4つの構造化データに対してjson形式で回答してください」と命令をすると、それぞれのタイトルに対して構造化した結果を出すことができます。日本語の性能が高いということで、英語ではどうかといった疑問があると思いますが、英語に関しても世界トップレベルの言語モデルと同じくらいの性能を出しています。Llama2というMeta社が開発した英語専門の言語モデルと比べて、ほぼ同じくらいの英語ベンチマークの結果を出しています。例えば、「日本語を英訳してください」といえばすらすら出てきますし、英語だけではなくプログラム言語を「こういうかたちのコードを書いてください」といえば、コードをはき出してくれます。英語、プログラム言語、そして今、中・韓・イタリア・ドイツ語を学習していますので、多言語での回答ができると思います。

■柔軟なカスタマイズ
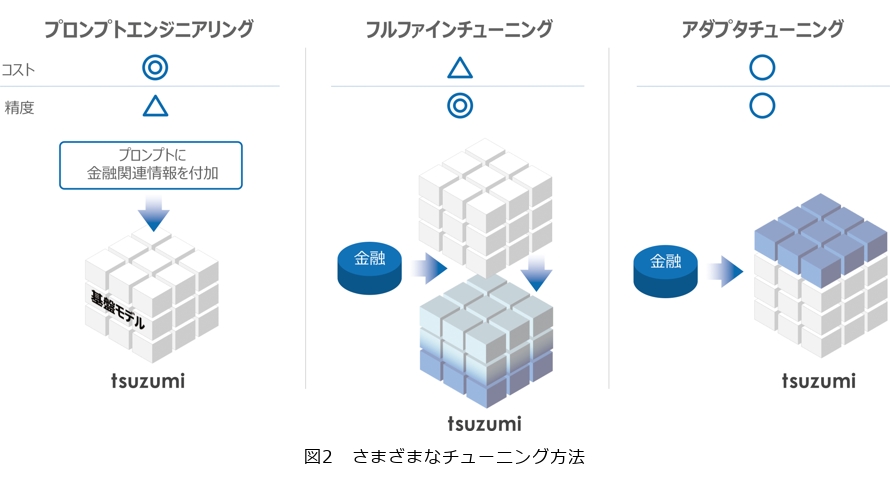
3番目の特長が柔軟なカスタマイズです。言語モデルは、基盤モデルと呼ばれるものがあり、ある程度汎用的な質問に対して答えることができますが、例えば、金融に詳しいものとか、あるいは公共分野に詳しいものとか特化型を行うにはチューニングが必要になってきます。図2に示す3種類のチューニングあり、図2左がプロンプトエンジニアリングです。これは基盤モデルに対して入力するときに金融関係の情報を入れると、金融特化型の質問に答えられるようなります。図2中央がフルファインチューニングで、これは基盤モデルに対して、金融関係のデータをもう一度再学習させて、パラメータ全体を変えていくことによって金融特化のモデルをつくるものです。図2右がアダプタチューニングで、基盤モデルはそのままにして、青い帽子をかぶせるみたいにそこに金融の専門知識を追加したものです。それぞれコストと精度の関係で、優れているところと優れていないところが出てきます。例えば、このようなチューニングができると基盤モデルを中心に業界に特化させたり、あるいは企業や組織に特化させたり、最新情報にアップデートさせたり、さらに、タスクに特化することで要約、翻訳等、新しいタスクを学習させることによって、機能を追加することもできます。
図3は金融業界のファインチューニングの例です。右がチューニング前のデータで、左が金融業界にファインチューニングにした後のものです。「東京証券取引所の市場区分について各区分の説明をしてください」という質問に対して、右はかなり古い状態で、東証一部、二部とかジャスダックとかマザーズが出ていますが、左は2022年の4月4日以降に東証が新しい区分を設けたこと(プライム、スタンダード、グロース)をちゃんと学習して回答できているのが分かると思います。

■マルチモーダル
4番目の特長がマルチモーダルです。今まで言語モデルに関しては言語を入れて言語のアウトプットを得るというモデルが一般的でしたが、今回のマルチモーダルは、視覚や聴覚等を追加することができるようになりました。例えば請求書のデータに加えて、言語で「10%の消費税を抜いた合計金額はいくらですか」という質問をします。そうするとLLMは、この請求書の単価と数量の欄を見ながら掛け算をして合計9500円と回答を出します。
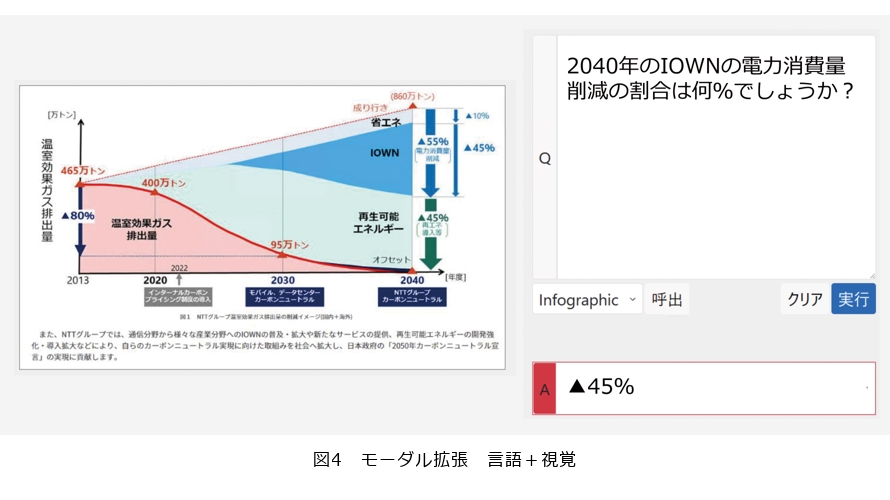
もう1つの例が図4左です。NTTが出したグリーンビジョンのグラフですが、この複雑なグラフを見せながら、右上にある「2040年のIOWNの電力消費量削減の割合は何%でしょうか」と質問をします。このような複雑な図でも、ここが正解だというものを言語モデルが分析して、答え45%と出しています。このように、いろいろな図と質問を組み合わせながら回答することができます。
ではどのようにして4つの優れた特長を実現できたか、NTT研究所の技術力について紹介します。
NTT研究所の技術力
図5は論文数をランキングしたものです。これは米国のベンチャーキャピタリストがまとめて毎年報告しているものです。NTTは世界で12位、国内では1位の順位となっています。1位から11位を見るとGAFAのように、米国、中国の非常に大きいITベンダがあります。彼らは研究費を何10倍も使い、研究員は何倍もおり、それでもかなり効率良く研究を行っており、このようなランキングを実現できています。また、言語モデルはAI分野の中でも自然言語処理が非常に重要ですが、その分野に限ってのランキングでは、国内ではもちろんNTTがナンバーワンの論文数を誇っています。国内の言語処理学会でも表彰件数でナンバーワンをとっています。長い歴史と研究の積み重ねを持って、LLMの開発に挑みました。今回の開発にあたり、学習データがどれだけ素晴らしいものを用意できるかがポイントとなり、1兆以上のトークン数(単語数)を用意しました。言語の種類では日英だけではなく、21言語さらにプログラミング言語の学習をしています。領域的にも専門分野からエンタテインメント(エンタメ)まで含めて非常に幅広い分野をカバーしています。さらに、インストラクションチューニングが、事前学習でつくったモデルで、さらに人に近いかたちに持っていくための教師データです。この教師データが、NTTのノウハウにあたるところで、今まで40年間の歴史があり、日本語のいろいろなコーパスを活用して、生成AIに向いたチューニングデータを新規に作成しました。
今回のR&Dフォーラムでは11種類の展示を用意しました。代表的なものを紹介します。

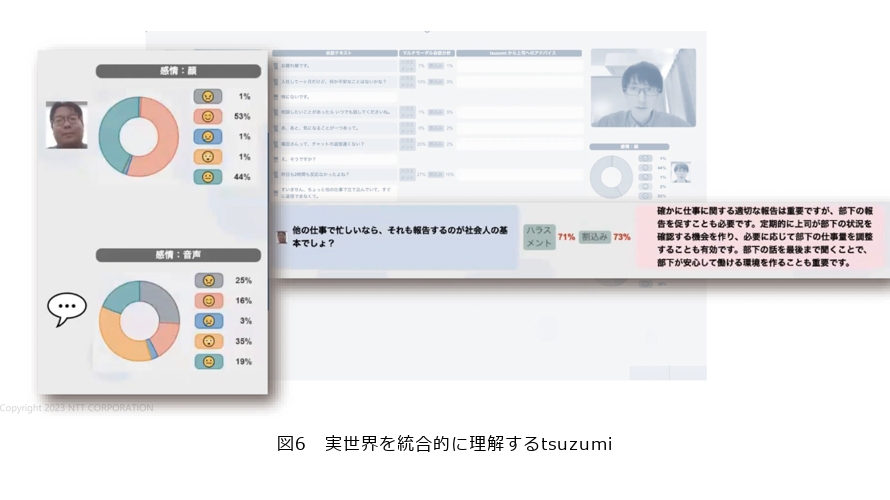
■実世界を統合的に理解するtsuzumi
上司と部下がオンラインのコミュニケーションで会話していますが、そのときに上司がパワハラをします。そのパワハラの様子をtsuzumiがちゃんとディテクトして注意を促します。「すいません。ちょっと他の仕事で立て込んでいてすぐに返信できなくて」「他の仕事で忙しいならそれを報告するのが社会人の基本でしょ?」このように上司がパワハラ的な発言をしますが、図6上は上司の顔、下は音声、この2つの情報を分析します。笑っているところ、怒っているところが何%位になるかを分析しています。次に図6左のブルーのところが上司がしゃべった言葉の内容です。そこに対して、ハラスメントの割合が71%になります。また、話している最中の割り込みが73%で、ハラスメント的なものが多くなります。それに対してピンクは、LLMが上司に対して行動変容のアドバイスをしているものです。「確かに仕事に関する適切な報告が重要ですが、部下の報告を促すことも必要です。定期的に上司が部下の状況を確認する機会をつくり、必要に応じて部下の仕事量を調整することも有効です。部下の話を最後まで聞くことで、部下が安心して働ける環境をつくることも重要です」と上司に対して適切なアドバイスをすることもできるようになっています。
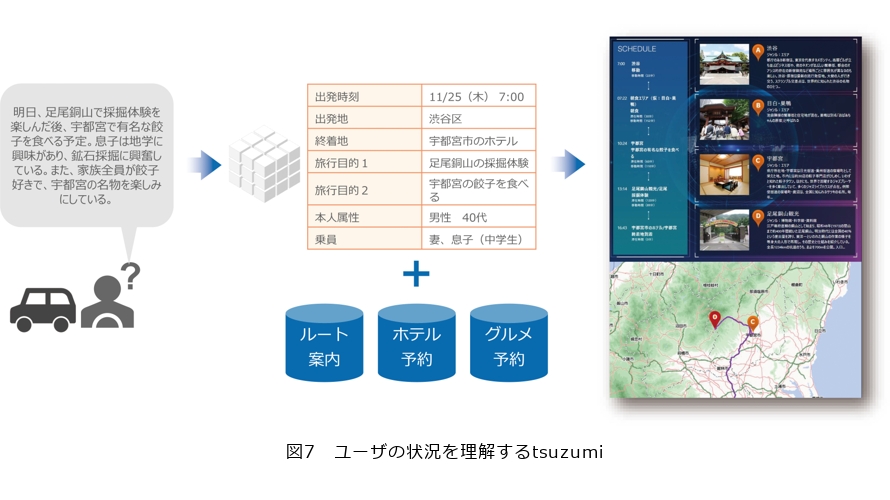
■ユーザの状況を理解するtsuzumi
tsuzumiは、ユーザの属性や好みなどを基に、道路の混雑状況などを踏まえて、具体的な旅行計画を作成します。図7左にグレイで書かれているところがユーザの発言です。例えば、「明日、足尾銅山で採掘体験を楽しんだ後、宇都宮で有名な餃子を食べる予定。息子は地学に興味があり、鉱石採掘に興奮している。また、家族全員が餃子好きで、宇都宮の名物を楽しみにしている」とカーナビに発言すると、出発時間が何時で出発地がどこでと構造化して分析してくれます。さらにルート案内、ホテル予約、グルメ予約という情報をWebからかき集めて、最終的に旅行計画をつくり上げて、ユーザに提案してくれます。
■身体感覚を持つtsuzumi
tsuzumiを搭載したロボットがユーザの要求に応じてメニューや、テーブル配置を整えてくれます。例えば「寒い冬の日に温まる夕食のテーブルをつくってください。左利きを意識して」と言うと、ロボットが分析して「温まる食べ物はカレーがいいよね、サラダもいいよね、季節感もあるので春巻きもいいよね、お茶は体を温めるよね」と回答をしながら実際に配膳していきます。また、左利きであることから箸とスプーンは右利きと反対の方向に置きます。このように説明しながらこのロボットが配膳することができます。
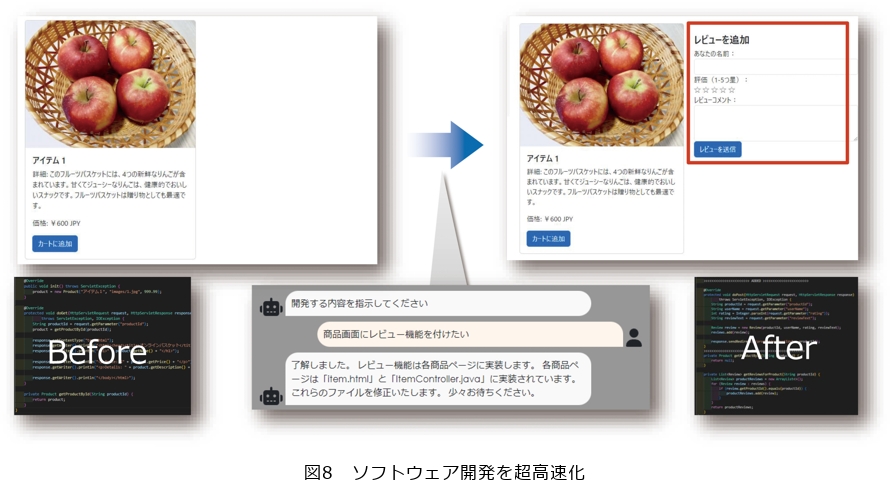
■ソフトウェア開発を超高速化
ショッピングサイトに新しい機能、例えばレビュー機能等を簡単に追加することができます。図8左のWebサイトは普通に商品を紹介しているだけで、レビュー機能がありません。これに対してtsuzumiに「商品レビューの機能を追加したい」と言葉で投げかけると、ソースを分析して簡単にレビュー欄が作成できます。
■次世代セキュリティオペレーション
次世代セキュリティオペレーションでは、セキュリティの専門家に代わってインシデント対応を会話形式で行ってくれます。例えばPCにウイルスが検知されたとするとtsuzumiが分析して、「あなたのPCにウイルスが検出されました、至急〇〇の対応をしてください」と順を追って、セキュリティの対応を促してくれます。
■セキュリティ
Webサイトを入力することによって言語モデルが分析して、フィッシングサイトを検出・判定することができます。なんとフィッシングサイトの判定精度が98%以上で、人間が見るよりも精度良く検出できます。
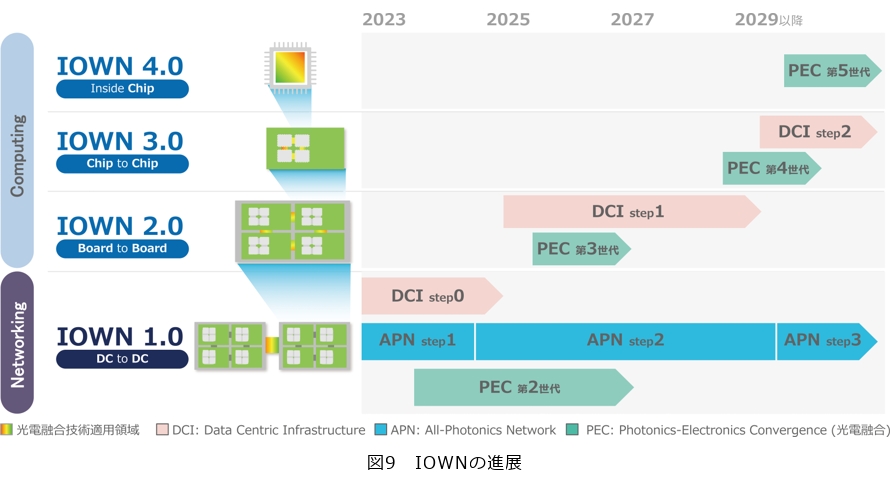
IOWNの進展
IOWNの進展について紹介します。まずIOWNのロードマップを改めて整理したいと思います(図9)。
IOWN 1.0はデータセンタとデータセンタを光でつなぐネットワーキングの技術です。IOWN 2.0はさらにそのデータセンタの中のサーバのさらに中のボードとボードを光でつなぐ技術です。IOWN 3.0は、さらにその中のチップとチップを光でつなぎ、そしてIOWN 4.0では、そのチップ中の光化というかたちで進化を遂げていきます。
次に、年代別にロードマップをみてみます。IOWNを構成する要素技術はいくつかありますが、例えば光電融合デバイス(PEC)では、IOWN 1.0、2.0、3.0、4.0というその世代の進化とともに、第2世代、第3世代、第4世代、第5世代と進化していきます。All-Photonics Network(APN)は、IOWN 1.0の中で機能を追加し、性能を上げて進化をとげていきます。さらにData Centric Infrastructureのスーパーホワイトボックスは、IOWN 1.0、2.0、3.0の進化、光電融合デバイスの進化とともに、Step 0、1、2というかたちで進化をとげていきます。このようなかたちでロードマップを進めていきます。
IOWN 1.0の中で、今年何が実現できたかを紹介したいと思います。まずAPNのプロダクト化がかなり進みました。APNはコアネットワークのAPN-I、エッジネットワークのAPN-G、ユーザ拠点に設置するAPN-T、ユーザ端末のOTN Anywhereから構成されます。それぞれ各社から具体的な製品が出ています。こういった製品を活用して、2023年3月に、NTT東日本・西日本から具体的なネットワークサービスを提供開始しました。これは100Gbit/sの専用線サービスで、ユーザがエンド・エンドで光波長を専有することができます。さらにこのOTN Anywhereを使うことによって、遅延時間の可視化や、バラバラになっている遅延時間を調整する機能も実現することができました。これを使い、2023年はいろいろなPoC(Proof of Concept)を実現しました。例えば、コンサート、eスポーツ、お笑い、ダンスのようなエンタメ分野のPoCを行いました。
エンタメの次は未来のデータセンタをAPNによって実現していきたいと思っています。従来のネットは遅延時間が結構多かったので、データセンタ間接続の範囲がかなり限定的でした。一説によるとデータセンタ間接続の距離は60kmぐらいが限界といわれましたが、大都市の中心部からこの範囲では土地が余っておらず、データセンタを増設するのが難しいのですが、APNを使うことでこのデータセンタ間の接続距離を60kmから100kmまで増やすことができます。この範囲ではまだまだ土地が余っているので、増設が可能になります。APNはこのようなデータセンタの拡充に非常に向いているのではないかと、いろいろなところで実証実験を行っています。さらに、首都圏だけではなく、日本各地の主要都市、さらには世界的なところに広がっていくと、世界規模のAPNのネットワークが構築できるのではないかと考えています。
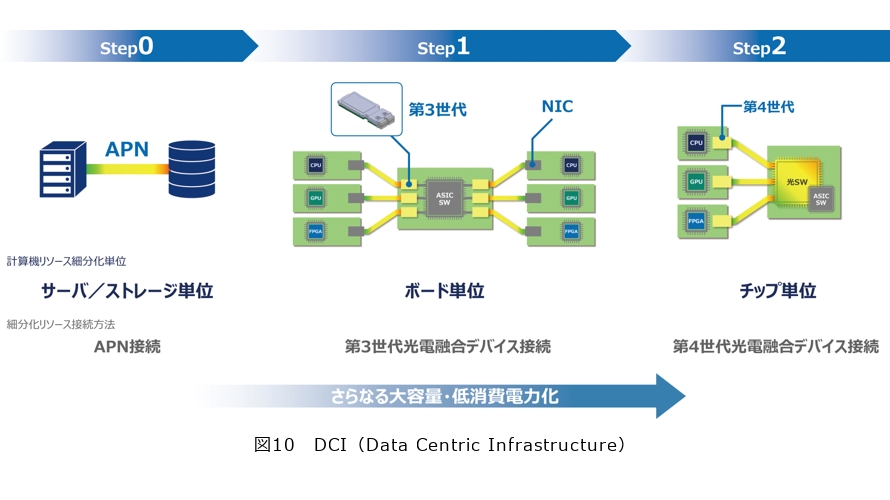
次にIOWN 2.0、3.0の状況を報告します。まずData Centric Infrastructure(DCI)です。こちらは計算機リソースを細分化することによって、データをその中心に添えて、最適に細分化した計算機リソースを配分します。これは省電力で高性能を実現する次世代のコンピューティングアーキテクチャです。
Step 0では、計算機リソースの細分化の単位をサーバとストレージと考えて、その間をAPNでつなぎます。次にStep 1では、細分化の単位がサーバの中のボードになります。このボードの間を第3世代の光電融合デバイスで接続することによって、超低消費電力、超高速なスイッチングを実現しようと考えています。さらにもっと進化するとStep 2になり、チップ単位で細分化してチップの間を第4世代の光電融合デバイスで接続することによって、低消費電力、高性能を実現していきたいと考えています。このStep 1を実現するためのキーデバイスが光電融合デバイス第3世代の光エンジンといわれるものです。図10の黄色い部分が1つひとつの光エンジンに相当します。ブロードコム様と一緒に実験していますが、チップが約5Tbit/sのスイッチング能力を持っており、1つひとつの光エンジンが3.2Tbit/sの伝送能力を持っています。これ1つで約5Tbit/sのスイッチング能力を持ったデバイスにすることができます。第4世代ではチップ間を光でつなぎ、第3世代よりも実装効率を6倍、電力効率を2倍と、さらに高性能化、低消費電力化を図っていきます。
LLM-IOWNの相互作用
LLMとIOWNの相互作用では、IOWNのDCI Step 0、APNとLLMを組み合わせた実験を行っています。横須賀に学習データがありますので、横須賀にGPUを持ち込みたかったのですが、電力や場所がなかったため、今回三鷹のGPUのクラウドを利用しました。その間をAPNでつないでリモートアクセスしています。本来であればこれだけ離れると、NFS(Network File System)も結構遅く、性能低下につながりますが、100km離れたところでもほとんど性能低下がなく実現することができました。具体的には0.5%ぐらいの性能低下です。この光スイッチを使って各CPU、GPUを光によりダイレクトにつなぐことによって、LLMの学習や推論を最小限、最適化されたような計算機リソースの組合せで行うことができます。GPUすべてをフルに働かせながら、なるべく最小限の計算機リソースで実現することをねらっています。
さらに未来の話になりますが、NTTがめざすAIの世界として、AIコンステレーションというものを考えています。これは1つのモノシリックな巨大なLLMをつくるのではなく、小さく専門性を持ったLLMを複数組み合わせることによって、1つの大きなLLMをより賢く、より効率的に解くことができないか、ということで次世代のアーキテクチャを考えています。例えば人事部長、臨床心理士、トラックの運転手、小学校教諭のようなキャラクターを持ったAIが「人口が減っている我が地域の活性化に何が必要ですか」という問題に対して、それぞれが自分たちの意見を言いながら、その意見を組み合わせたり、あるいは合意形成を取ったり、たまに人が入ってインタラクションを取りながら1つの合意形成をつくっていく仕組みができないかと考えています。
今回、AIコンステレーションを実現するにあたり、sakana.ai様と業務提携を行い、これから共同研究等を進めていく予定です。このsakana.ai様は、今非常に注目されてるベンチャー企業で、実は創業メンバーがGoogle BrainのDavid HaさんとChatGPTのTの部分、Transformerの発明者の1人であるLlion Jonesさんです。この2人がつくったsakana.aiと、新しいLLMやAIコンステレーションの研究開発を行っていきます。
研究所の3つの覚悟
最後に、「研究所の3つの覚悟」を紹介します(図11)。
「知の泉を汲んで研究し実用化により世に恵みを具体的に提供しよう」は1950年にNTT研究所の初代所長吉田五郎が研究所のビジョンを語った言葉です。これは、「知の泉を汲んで研究し」という土台があって、その上に「実用化により」という開発のフェーズがあって、最後に「世に恵みを具体的に提供しよう」と、この3つを積み重ねることによって実現できるものだと思っています。
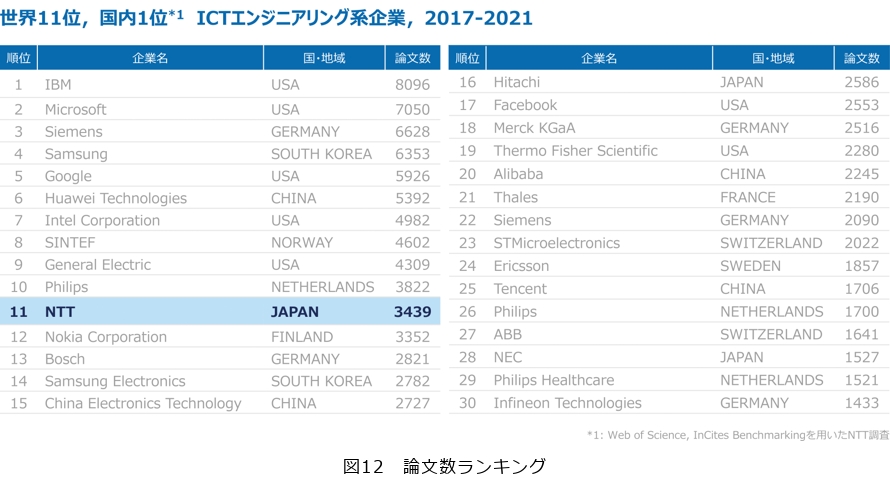
まず一番大事なことが1番下にある研究のところ「知の泉を汲んで研究し」です。図12はAIだけではなく、エンジニアリング全部の領域における論文数のランキングですが、NTTは11位になっています。世界トップクラスの研究も実はいろいろあり、音声認識、情報セキュリティ、光通信、量子計算機等をGoogleやIBMにも勝って、世界1位の論文数を誇っています。このような実績をさらに順位を上げる、あるいは世界ナンバーワンの研究領域をもっと増やすことを推し進めていき、世界最高峰の研究地位を確立していきたいと考えています。これが覚悟の1番目です。
次が真ん中の開発のところ「実用化により」です。これは前述のとおり、IOWNとLLMの重要な2つのキーファクターを確実に実用化していくことを覚悟の2番目としたいと思います。
最後は社会実装のフェーズである「世に恵みを具体的に提供しよう」です。これに関しては、2023年6月に研究開発マーケティング本部を新しくつくりました。これまでは研究所と研究企画部門が一体となってお客さま、パートナー企業、事業会社の方と連携を取っていました。これに対して研究開発マーケティング本部をつくり、マーケティング部門、アライアンス部門と協力することによって、より幅広い活動をしていきたいと考えています。ここで最後に述べる覚悟が研究成果、開発成果を社会に実装をしていくものです。
NTT研究所は、この3つの覚悟を持って、R&Dを推進していきたいと思います。