2022年6月号
特集
光デバイスによるリザーバコンピューティングの物理実装
- 光回路
- リザーバコンピューティング
- 機械学習
NTTでは、AI(人工知能)処理の抜本的な高速化・低電力化に向けて、光によるニューラルネットワーク演算技術を検討しています。本稿では、特にリザーバコンピューティング(RC)と呼ばれるニューラルネットワークモデルの光デバイス実装について説明し、その性能と応用に向けての取り組みについて紹介します。
中島 光雅(なかじま みつまさ)/鶴谷 拓磨(つるがや たくま)
田仲 顕至(たなか けんじ)/橋本 俊和(はしもと としかず)
NTT先端集積デバイス研究所
光技術とAI時代のコンピューティング
現在の情報処理技術は、長距離の光ファイバ通信をはじめとする大容量な光伝送技術の進展によってもたらされてきました。このような技術開発の過程で、光・電子技術間の障壁は低くなり、集積回路上に光回路・電子回路の混載する光電融合という技術が現実味を帯びる時代となりました(1)。光電融合技術は、光による効率的な情報伝送をより微小なスケールで実現する方向で進展していますが、さらなる発展形として、情報処理や演算まで光回路上で実行する「光コンピューティング」という技術分野が近年注目を集めています(2)(3)。この背景には、先述したような光通信の進展による技術進化のほかに、AI(人工知能)分野の爆発的な進化が関係しています。
AIにおける情報処理には、人工ニューラルネットワーク(ANN)と呼ばれる脳の処理にインスパイアされた計算アルゴリズムが活用されています。この計算の中身は、膨大な量の行列演算と非線形処理によって構成されており、近年のICT社会の進展に伴って、ますます計算需要が増大しています。このような背景で、AI計算の高速化や低電力化に向けたANN処理専用の計算回路の研究開発が活発化してきています。光演算では、従来の電子回路上のデジタル演算とは異なり、光信号の強度や位相のようなアナログ的な値を情報とみなし、その伝搬や干渉を利用して計算します。例えば図1(a)のように光干渉系に光信号を入力すると、互いに干渉し合った光信号が出力されますが、このときの出力信号は入力信号に対してある行列積を演算した結果としてとらえることができます。この演算は光の伝搬と干渉のみで実行され、原理的に高速かつ低電力に演算可能です。さらに時間、波長、空間といった光特有の多重化技術を利用して、大規模な並列演算を実現することもできます。図1(b)のように、光干渉系の構成を適切に設計することで種々のANN向けの演算を実行することができます。光演算はデジタル回路のようにさまざまな計算に柔軟に対処することは困難ですが、行列積のような特定の演算を効率的に実行できます。一般的なコンピューティング用途としては、光演算は電子回路による演算に優位性を見出せず、研究が停滞した時期もありましたが、AI処理の専用回路の台頭によって、再び実用化に向けた取り組みが世界的に始まっています。
NTTでは、光演算を上記のような特定の演算処理に適用することで、将来的なAI計算の抜本的な低電力化・高速化をめざしています。本稿では、特にリザーバコンピューティング(RC)と呼ばれるニューラルネットワークの光デバイス実装について紹介します。
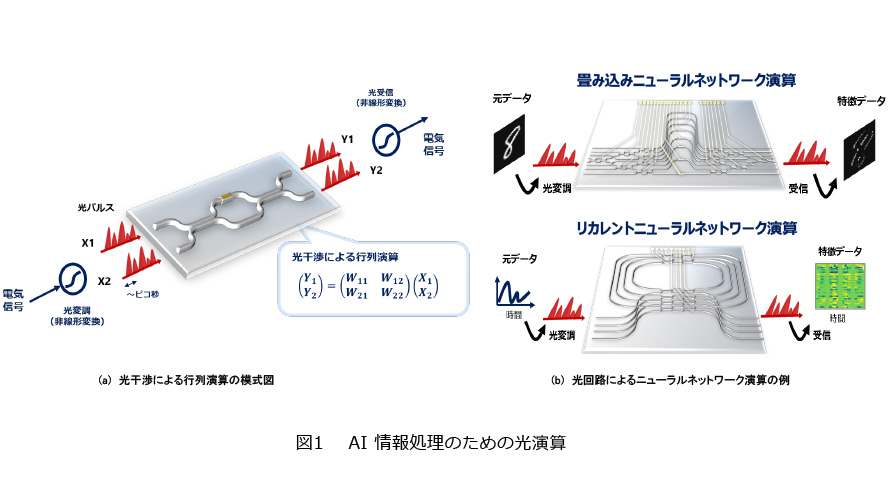
光デバイスによるリザーバコンピューティングの物理実装
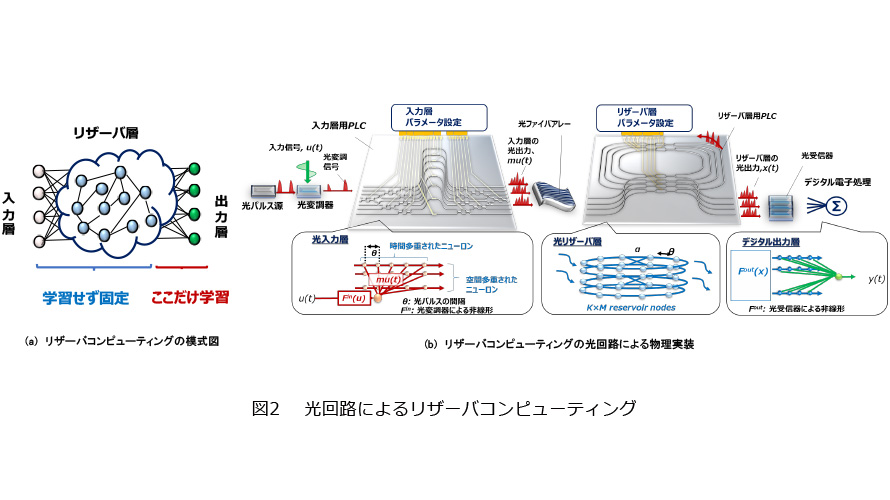
RCは図2(a)のような、回帰的な接続を持つリカレントニューラルネットワークの一種です。最大の特徴は、入力層とリザーバ層と呼ばれるネットワークの重みをランダムに設定し、学習しないという点です。出力層のみを最小二乗法等の線形回帰で学習しますが、この処理は通常のANNモデルで利用される学習法(誤差逆伝搬法)に比較し非常に簡便です。このように単純化した構成にかかわらず、良好な性能が得られることが報告されています。RCは、人間の小脳のような情報処理をしているといわれており、高速な学習に適しています。光実装するうえでも、大半の処理をパッシブな光回路で表現できますので、光実装と相性が良いといえます。
図2(b)に光実装したRCの模式図を示します(4)。入力層用の光回路では、光信号が時間・空間方向に重み付けされます。リザーバ層用の回路では、リング状の光回路アレーが回帰的な結合を表現します。この出力信号を、光受信機(PD)を介して電気信号へ変換し、デジタル回路上で出力層に相当する重み付けをすることでRCの基本動作を模倣します。ここで、一般的なANNモデルでは、光回路で表現される重み(例えば、光干渉系の位相)を学習とともに動的に更新していく必要があり、これが学習時間を律速してしまいます。一方、RCでは光回路部に相当する結合をランダムに固定したままでいいので、この処理ボトルネックを解消できます。出力層の重み付け処理はデジタル回路で実行する必要がありますが、この操作はコヒーレント光通信における信号歪の補償と同様な操作であるため、従来の通信技術を流用した高速な処理が原理的に可能です。
前述の光デバイスを、光通信で培った平面光波回路(PLC:Planar Lightwave Circuit)と呼ばれる技術を用いて、実装しました。回路内で表現可能なニューロンの数が性能に大きな影響を持ちますが、構成の工夫とPLC技術によって、512ニューロンが実装されています。これは、従来の光チップ実装と比較し、30倍以上の値になります。このデバイスを用いてMNISTと呼ばれる画像認識のベンチマークタスクを解かせたところ、最大で91.3%という分類精度が得られました。これは、光チップ実装としては最高精度となります。また光回路内では、1画像当り約17.1nsという高速な処理が可能であることを実験的に確認しました。光回路での、1秒間当りの計算回数は20兆回と見積もられ、これは最新のCPU等の計算性能を凌駕する値です。さらに波長多重などの光の自由度を利用することで、同一チップ中で複数の演算を並列的に実施することも可能であり、原理的には、1秒当り1京回に相当する計算を行うことも可能です。
光リザーバコンピューティングの応用に向けて
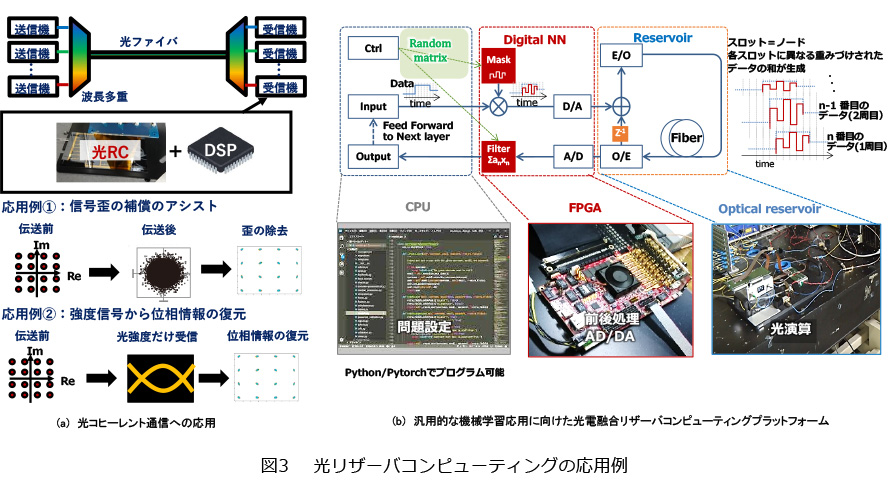
前述のように光演算は高速な処理が可能ですので、高速処理を必要とする応用に特に適しています。そのような応用例として、図3(a)のような光通信用の信号処理があります。現在の光通信では、デジタル信号処理装置(DSP)を用いて受信波形の歪を補償していますが、通信の大容量化に伴ってDSPの処理の負荷が課題となっています。そこで、信号処理の一部を、RCをはじめとした光ANNへ担わせる方式について検討が進められています(5)。NTTでは、このようなDSP処理負荷のオフロードだけでなく、従来のコヒーレント受信器の光フロントエンドの構成を抜本的に小型簡素化可能な手法についても検討を進めています(6)。
さらに、より一般的な機械学習のタスクへと適用することも検討しています。その実現に向けては、ハードウェアを意識せずに、ソフトウェア上で定義したタスクを通常のコンピュータと同じように駆動できることが望ましいといえます。そこで、図3(b)のようなFPGAと光RCが連携したテストプラットフォームを構築しました。ユーザは一般的に機械学習に用いられる言語である、Python/Pytorchから光RC系を駆動することが可能です。また、RCの物理実装の中でもっとも高い性能を達成できることを実験にて確認しています(7)。現状では、まだまだCPU/GPU等を用いたデジタル演算には劣る点も多いですが、光の特徴を活かした応用展開に向けて検討を進めています。
光演算性能向上に向けて
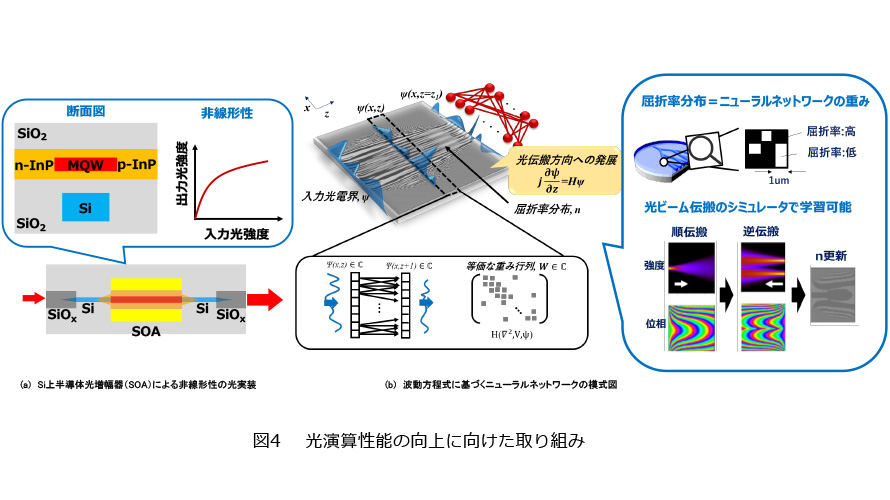
さらなる演算性能の向上に向けては、光デバイス性能の向上が欠かせません。例えば、従来の光通信では信号歪の要因となるためにむしろ抑制されてきた非線形な光学効果も、光学的なニューロン実装として積極的に活用する必要があります。石英で構成されるPLC単体ではこのような非線形機能の発現は困難なため、前述の物理実装では非線形性に関しては光電変換による電子的な処理に頼っていました。一方、光非線形素子として機能するIII-V族半導体光デバイスをSi(シリコン)上に集積することで、光回路上でもニューロンの非線形活性化を光学的に表現することが可能です。そこで、図4(a)のような半導体光増幅器(SOA)がSi上に集積された素子を活用し、非線形なリザーバ層を光学的に実装してベンチマークタスクによる性能評価を行いました。実験結果から、光学的な非線形処理を用いた場合も光電的な処理にそん色ない良好な性能が得られることが分かりました(8)。この成果を基に、さらなる演算機能の光回路への集積に向けて検討を進めています。
また、先端的な機械学習モデルへの適応に向けては大規模な光集積も必須です。最先端なANNモデルでは、およそ100億ものパラメータが存在しますが、図1(a)のような光干渉系はおよそ100μm角と大きいため、現実的なサイズでの実現は困難です。そこで、発想を転換し、図4(b)のように、光の波動伝搬自体をニューラルネットワークとしてみなす枠組みを提案しました。また、この枠組みでは、光回路中の屈折率の分布自体がニューラルネットワークの重みと等価であることを見出しました(9)。屈折率分布はおよそ1μm角のオーダで変化させることが可能であるため、面積比で従来方式の100万倍程度の大規模実装が可能となります。また、シミュレーション解析では、先端的なネットワークモデルとそん色のない性能が得られることを確認しています。このような新規な処理方式等も取り入れつつ、光演算全体の性能向上に向けて取り組みを進めています。
おわりに
光コンピューティングによるAI演算の高速化・低電力化に関する取り組みについて述べました。光の特徴を利用することで、高速・低電力な並列演算が可能となり、将来的なAI処理応用への期待が高まっています。一方で、すでに成熟した従来型のコンピューティングに対する優位性を確立していく道のりは決して簡単なものではありません。本稿でも紹介したように、光デバイス単体の研究を超えて、アルゴリズムや具体的な応用例を合わせて考えていくことが、将来の光電融合型のコンピュータの実現に向けて肝要であると考え、今後も検討を進めていきます。
■参考文献
(1) 坂本・瀬川・佐藤:“ディスアグリゲーテッドコンピューティングのための光電融合技術,”NTT技術ジャーナル,Vol. 33, No. 5, pp.45-49,2021.
(2) 野崎・新家・納富:“ナノフォトニクス技術による光電融合アクセラレータへの研究展開,”NTT技術ジャーナル,Vol. 32, No. 8, pp.23-28,2021.
(3) B. J. Shastri, A. N. Tait, T. Ferreira de Lima, W. H. P. Pernice, H. Bhaskaran,C. D. Wright, and P. R. Prucnal:“Photonics for artificial intelligence and neuromorphic computing,” Nature Photonics, Vol. 15, pp.102-114, 2021.
(4) M. Nakajima, K. Tanaka, and T. Hashimoto:“Scalable reservoir computing on coherent linear photonic processor,”Communications Physics, Vol. 4, pp.1-12,2021.
(5) A. Argyris:“Photonic neuromorphic technologies in optical communications,”
Nanophotonics, Vol.1, pp. 897-916,2022.
(6) M. Nakajima and T. Hashimoto:“Phase-Retrieval Coherent Detection with On-Chip Photonic Linear Processing,”Frontiers in Optics, FW5E.2,2021.
(7) M. Nakajima:“Physical Deep Learning with Biologically Plausible Training,”
arxiv-2204.13991, 2022.
(8) T. Tsurugaya, T. Hiraki, M. Nakajima, T. Aihara, N. P. Diamantopoulos, T. Fujii, T. Segawa, and S. Matsuo:“Reservoir Computing with Low-Power-Consumption All-Optical Nonlinear Activation Using Membrane SOA on Si,”CLEO: Science and Innovations, AW2E.5,2021.
(9) M. Nakajima, K. Tanaka, and T. Hashimoto:“Neural Schrödinger Equation: Physical Law as Deep Neural Network,”IEEE TNNLS,pp.1-15, 2021.
DOI: 10.1109/TNNLS.2021.3120472

(上段左から)中島 光雅/田仲 顕至
(下段左から)鶴谷 拓磨/橋本 俊和






光コンピューティングは、デバイス単体レベルからシステム、アルゴリズムまで多岐にわたる学際的な分野です。NTTの多様な研究領域を活かし、革新的な成果創出に向けてチャレンジしていきます。